XV6 Operator System: 01-The Boot Loader
在开始讲述内容前,我必须声明的是:本系列笔记是针对于有一定操作系统基础的(包括不限于:写过简单的OS,学校课程所学的操作系统课等),因此部分内容个人认为是读者应该知晓的知识,因此不会做过多赘述。
Specify Memory Layout
在我们正式介绍xv6-riscv源码之前,我们首先得了解一个操作系统的内存布局。也就是,xv6-riscv的入口点以及各个section的布局。
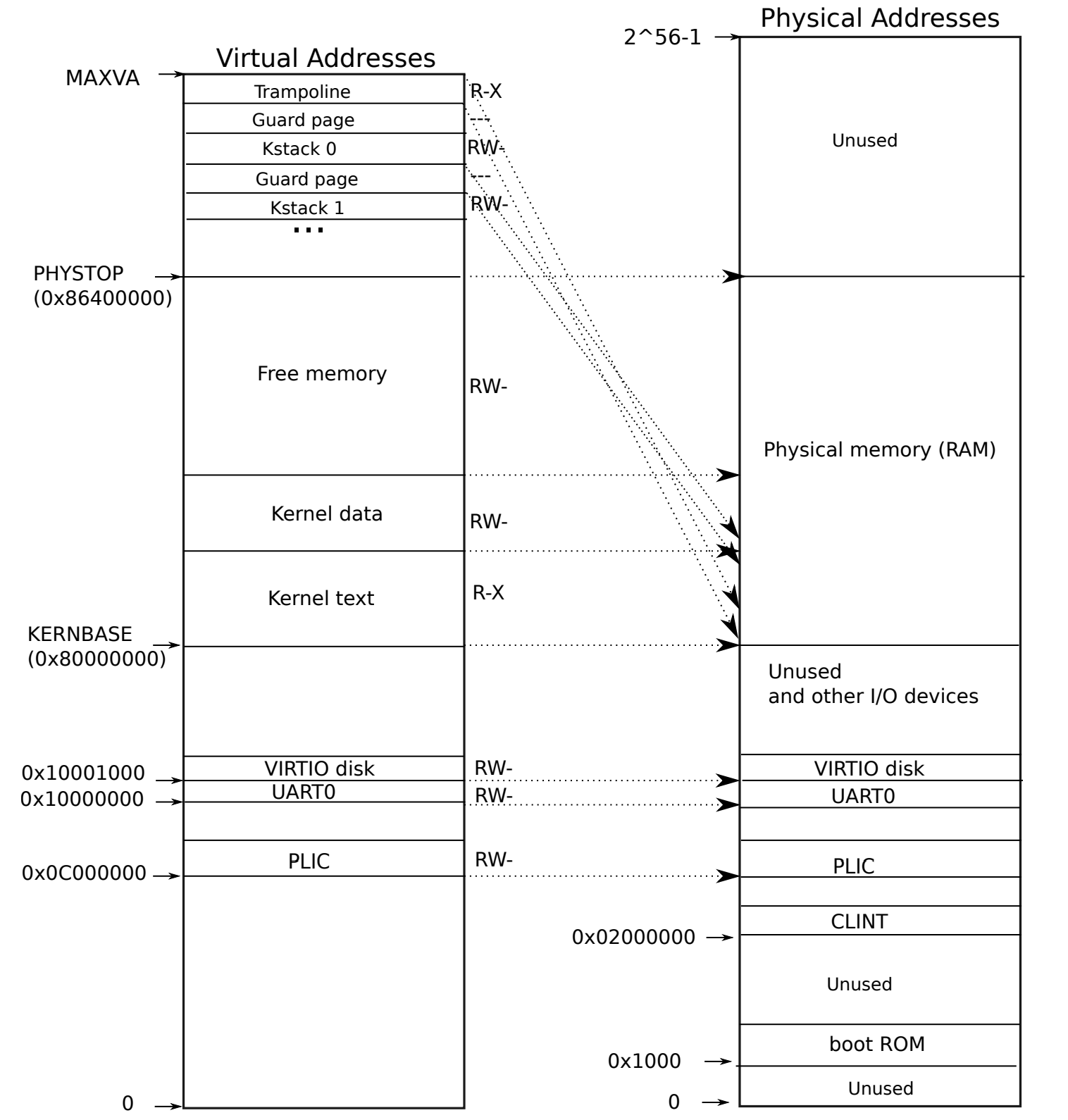
我们可以看见,xv6-riscv操作系统的入口点,也就是KERNBASE位于物理内存的0x8000'0000处,并且结束于PHYSTOP(也就是物理内存的0x8640'0000)处,这样我们就得到:
$$
PhysicalMemory(ram) = 0x8640’0000 - 0x8000’0000 = 0x640’0000
$$
现在,现在让我们根据上面的内存布局图来对照对应的link-script:
1 | OUTPUT_ARCH( "riscv" ) |
我们逐一的来分析该kernel.ld文件的含义。
对于OUTPUT_ARCH( "riscv" )来说,是指明我们的生成架构是risc-v,而ENTRY( _entry )指定程序的入口点为 _entry。这是一个非常重要的配置,用于确定当程序开始执行时,处理器应该跳转到哪个地址开始执行代码。在操作系统内核和许多其他类型的程序中,这个地址通常是初始化代码的起始位置。
我们在上文已经知道,我们设置程序的入口地址为0x8000'0000,也就是说,我们将_entry的入口地址绑定为0x8000'0000,因此,可以看见这一语句:
1 | . = 0x80000000; |
也就是说,我们最终生成的镜像文件中的以下section会从该地址处开始。同时,这也是qemu-riscv默认加载内核的地址。
在qemu risc-v virt.c文件中,有该定义:
1 | static const MemMapEntry virt_memmap[] = { |
具体qemu-riscv执行的语句为:
1 | riscv64-linux-gnu-ld ... -T kernel.ld ... -o kernel ... |
介绍完入口点后,我们就应该介绍各个section了,有关于ELF Sections的介绍,请读者自行查阅维基百科或elf file pdf。
根据上方的内存映射,我们可以看见,第一个应该分配的便是.text section,其中,在Kernel text的映射中,Trampoline被映射到.text中(关于trampoline在后续讲述,此处不做过多描述,只需要知道的是: trampoline的大小被分配为一个页),因此可以看见kernel.ld中的语句:
1 | .text : { |
关于.text的含义,这里做出简要介绍:This section holds the “text”, or executable instructions, of a program,也就是说,.text段是代码文本和指令存放的区域。现在,让我们来逐语句解释上面的语句含义:
*(.text .text.*): 这一行指定了在链接时将所有以.text开头的段(section)和所有.text.后跟任意字符的段都放置到.text段中。. = ALIGN(0x1000): 这一行将当前位置(.)对齐到0x1000(即$4MB/page$)字节的边界。_trampoline = .: 这一行将当前位置(.)的值赋给名为_trampoline的符号,这对应了Trampoline的映射*(trampsec): 这一行将所有名为trampsec的段(如果有的话)添加到.text段中,其具体含义后续介绍. = ALIGN(0x1000): 再次将当前位置(.)对齐到0x1000字节的边界,以确保.text段的大小是页面大小的整数倍ASSERT(. - _trampoline == 0x1000, "error: trampoline larger than one page"): 对Trampoline的映射大小做出检测PROVIDE(etext = .): 这一行定义了一个名为etext的符号,并将其值设置为当前位置(.),这定义了一个类似于end_text的符号标识
第二个映射的内存布局便是Kernel data,一般而言,data是有两种的,只读数据以及可读可写数据。在ELF文件格式中,.rodata通常是放于.text之后,.data之前的。
1 | rodata : { |
关于.rodata的含义:These sections hold read-only data that typically contribute to a non-writable segment in the process image,也就是说,.rodata段是由只读数据构成的。现在,让我们来逐语句解释上面的语句含义:
. = ALIGN(16): 这行代码将当前的地址对齐到16字节边界。*(.srodata .srodata.*): 表示将所有在链接时发现的.srodata段和以.srodata.开头的段放入当前段(即.rodata段)。这包括类似.srodata和.srodata.foo这样的段。这些段通常包含只读数据。*(.rodata .rodata.*): 表示将所有在链接时发现的.rodata段和以.rodata.开头的段放入当前段(即.rodata段)
1 | .data : { |
紧接着的分配的.data和.bss段,这里不再赘述,而.data的含义为: These sections hold initialized data that contribute to the program’s memory image,也就是说,.data段包含了初始化的数据;而.bss段的含义为:This section holds uninitialized data that contribute to the program’s memory image,也就是说,.bss包含了未初始化数据。
至此,xv6-riscv简单的内存布局便设置好了,现在,让我们把视角从内存布局处移到内核入口点。
Kernel Entry Point
不用多说,我们的内核环境肯定是”裸机的”,因此,我们需要根据上面的内存布局设置的入口点,设置我们的入口函数。而如何进入我们的入口函数,就需要通过汇编直接跳转到入口地址了。
1 | .section .text |
我们可以看见一个很关键的地方:.text段的声明,我们在上面一节中知道,Kernel text也就是.text是从0x8000'0000地址处开始的,并且,.text是存储代码文本和程序指令的地方。因此,当内核启动时,会启动_entry作为入口点,而该入口点,就进入了上面的这一块代码。
现在,让我们来逐语句的解释其含义:
1 | #define NCPU 8 // maximum number of CPUs |
我们首先要为每一个hart分配对应的内核栈,而有一个比较有趣的现象是,__attribute__ ((aligned (16))),这与我们分配.bss的时候一致,需要进行十六个字节的对齐。
1 | li a0, 1024*4 |
这里是设置了每一个hart对应的内核栈大小。
1 | csrr a1, mhartid |
从mhartid寄存器中读取硬件线程ID,计算出每一个hart自身对应的内核栈的偏移量,然后设置sp指针指向当前hart的专属内核栈位置。
1 | call start |
最终转跳到start函数中,而start函数,便是整个内核的开始位置。下面给出对应的实际汇编代码:
1 | 0000000080000000 <_entry>: |
由此,可以看见,_entry入口点确实在0x8000'0000地址处,而最终也会正确的转跳到start函数中。同时,在start函数中,使用的sp指针也是独属于当前hart的内核栈。
RISC-V Hart
在
RISC-V架构中,hart代表硬件线程(hardware thread), 在一个多核处理器中,每个核心可以有一个或多个hart。每个 hart 在系统中都有一个唯一的标识符,称为 hart ID。在RISC-V架构中,可以通过读取特定的CSR(Control and Status Register)来获取当前执行的hart的ID,通常是mhartid寄存器。
