Sharing data between threads
使用线程来实现并发的一个潜在的好处就是能够很容易、直接地在它们之间使用共享数据。因此,本篇笔记就是来讨论一些围绕共享数据的一些问题。
如果你在线程之间共享了数据,你需要规定哪个线程可以在何时访问哪位数据,以及如何将任何更新传达给关心该数据的其他线程。但是不正确的共享数据的使用却是线程导致$BUG$的最大的一个原因。
本篇笔记是关于在$c++$中线程之间安全地共享数据,避免可能出现的潜在问题,并最大限度地提高收益。
Problems with sharing data between threads
当我们提到这个的时候,共享数据的问题全都是因为线程修改数据而导致的。如果所有的共享数据都是只读的,那么不会发生任何问题。因为一个线程读取数据不被会另一个读取相同数据的线程所影响。但是如果一个或多个线程开始修改数据,就可能导致许多问题的产生。
一个广泛的概念是:invariant(不变量)————关于特定数据结构始终为真的陈述。这些不变量经常在更新过程中被破坏,特别是在数据结构非常复杂或更新需要修改多个值的情况下。
现在考虑一个双向链表,其中每一个节点都含有一个指针,其指向链表中的下一个节点和上一个节点。其中的一个不变量为:如果你从一个节点($A$)通过next指针跟随到下一个节点($B$),那么就有节点($B$)的指针通过prev指针指向上一个节点($A$)。如果我们想要删除一个节点,那么节点的两侧就应该相互指向对方;一旦一侧的指向发生了改变,那么不变性就被破坏了;直到另一侧也发生了该相应的改变,不变性重新被建立。
这里给出下图中每一步的解释:
a. 标识$N$节点会被删除
b. 更新$N$节点的上一个节点指向$N$节点的下一个节点
c. 更新$N$节点的下一个节点指向$N$节点的上一个节点
d. 删除$N$节点
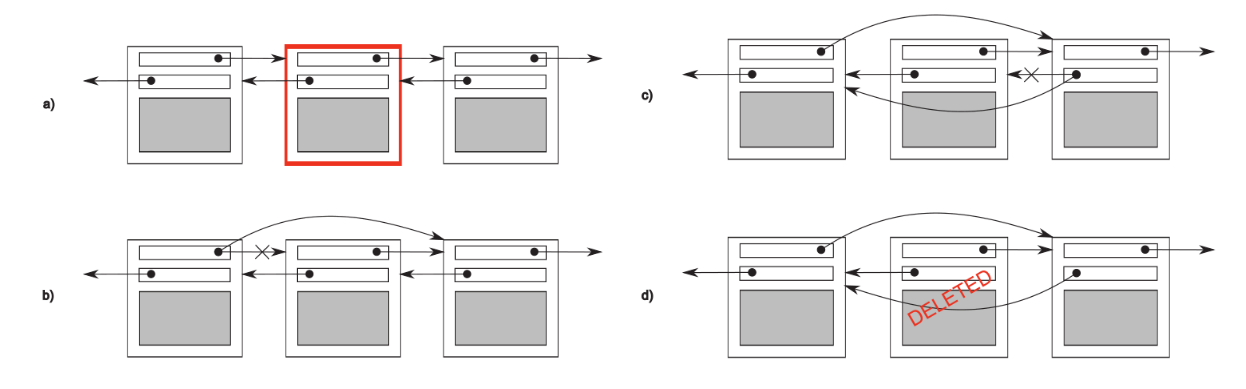
我们可以看见,在$b$和$c$步骤之间,由于一个方向上的连接关系和另一个方向上的连接关系不一致,因此不变量被打破。
修改线程间共享的数据最简单的潜在问题是破坏不变量,如果一个线程正在读这个双向链表而另一个正在删除双向链表上的一个节点,那么读线程就很可能看见这正在被删除时的链表,因此不变量就被打破了。而根据读线程看到的删除状态的不同,其最终的结果也有所不同。
- 如果读线程从左往右读取,那么它就可能直接跳过被删除的节点$N$
- 如果删除节点的线程正好删除最右边的节点,那么就可能永久性的破坏链表的结构并且最终导致程序崩溃
因此,又一个问题产生了,一个并发代码中最常见的$bug$原因之一:race condition(竞争条件)。
Race Condition
假设你想要在电影院购买一张电影票,并且有多个窗口办理购买流程。如果你现在已经对售票员述说了购买需求,而刚好有另一位人在另一个窗口和你买了同样的座位,那么你是否能够成功购买到你想要的座位就取决于你先订票还是他先订票。这就是一个race condition(竞争条件)的一个例子。
在并发中,竞争条件是指任何结果取决于两个或多个线程上操作执行的相对顺序的情况;线程竞相执行各自的操作。在大多数情况下,竞争条件是良性的;但是,一旦竞争条件导致不变量被破坏,就会可能导致问题的发生。在我们讨论竞争条件时,这个术语race condition通常指的是problematic race condition。在$c++$标准中,还特别使用data race来特指因为并发修改了单个对象的数据导致的一种竞争条件类型。而data race会产生未定义行为。
problematic race condition通常发生在完成一个操作需要修改两个或多个不同的数据块时。竞争条件通常是难以被发现和重现的,因为其出现的几率是很小的。如果修改是作为连续的$CPU$指令进行的,即使数据结构正在被另一个线程并发访问,问题在任一运行中出现的概率也很小。随着系统负载的增加和操作执行次数的增加,问题出现的可能性也会增加。这种问题往往会在最不方便的时候出现,几乎是不可避免的。由于竞态条件通常是与时间有关的,当应用程序在调试器下运行时,它们往往会完全消失,因为调试器会影响程序的时间,即使只是稍微地。
因此,如何在多线程代码中避免竞争条件就是必须的事情。
Avoiding problematic race condition
这里有很多种方式来解决有问题的竞争条件。最简单的一种方式是用保护机制包装数据结构,以确保只有执行修改的线程才能看到不变量被破坏的中间状态。从访问该数据结构的其他线程的角度来看:对于数据结构的修改要么还未开始,要么已经结束。针对于这一点,$c++$标准库提供了许多机制来处理(将在本篇笔记中介绍)。
另一种选择是修改数据结构及其不变性的设计,以便将修改作为一系列不可分割的更改进行,每个更改都保持不变性。这种被称为lock-free programming(无锁编程),但这往往很难做到。如果你在这个层面上工作,内存模型的细微差别和确定哪些线程可能会看到哪些值的问题可能会变得复杂。内存模型在第五篇笔记中有详细介绍,而无锁编程则在第七篇中进行了讨论。
处理竞争条件的另一种方法是将对数据结构的更新作为transaction(事务处理),就像对数据库的更新在事务中完成一样。在其中,有一个术语叫做STM(software transactional memory),它是一种并发编程模型,旨在简化多线程程序中的共享内存访问和同步。它提供了一种类似于数据库事务的机制,使开发人员能够定义一系列原子操作,这些操作要么全部成功执行,要么全部回滚,就像一个单个不可分割的事务一样。但是目前而言,在本系列笔记中不做过多介绍。
而在$c++$标准库中的最常见的保护共享数据的方式是:mutex(互斥锁)。
Protecting shared data with mutexes
如果你有一个共享的数据结构,就比如在前面所提到的双向链表。你想要保护它免受竞态条件和可能导致的破坏不变性的问题,那么将所有访问该数据结构的代码标记为mutually exclusive(互斥),这样就使得当一个线程执行时,任何试图访问该数据结构的其他线程都必须等待这个线程完成。这将使得除了进行修改的线程之外,其他线程无法看到破坏的不变性。这样做将确保线程在修改时才能看到破坏的不变性。
因此,你可以使用$c++$所提供的同步原语mutex。在你访问这个共享数据之前,你首先得将mutex上锁,当你完成访问或其他操作后,再将mutex解锁。然后,线程库确保一旦一个线程锁定了一个特定的互斥锁,所有其他试图锁定同一个互斥锁的线程都必须等待,直到成功锁定互斥锁的线程将其解锁。这就确保了所有线程所看到数据的一致性。
当然,在大多数时候互斥锁的存在能够解决许多问题,但是这绝不是唯一一种,并且在少数极端情况下,互斥锁并不是灵丹妙药,其可能产生dead lock(死锁)问题。
Using mutexes in C++
在$c++$中,你可以通过构造一个std::mutex的实例来创建一个互斥锁,使用lock()上锁和unlock()来解锁。从实际上说,并不推荐手动的进行lock()和unlock(),在$c++$中还提供了实现了RAII的std::lock_guard类模板,它在构造时锁定所提供的互斥锁,在销毁时解锁,确保被锁定的互斥锁总是被正确解锁。
1 |
|
从上面的示例中看出,这两个函数add_to_list和list_contains是互斥的,也就意味着list_contains永远不会在add_to_list修改链表的途中访问数据结构。 在$c++17$标准中,由于$CTAD$的存在,我们可以直接忽略到模板参数的显式声明。
1 | std::lock_guard guard( some_mutex ); |
在$c++17$标准中,还增加了一个增强版本的lock guard类:std::scoped_lock,当然,它也可以通过$CTAD$来省略模板的声明。
1 | std::scoped_lock guard( some_mutex ); |
CTAD, Class Template Argument Deduction
C++17引入的一个特性。它允许在使用类模板时省略模板参数,编译器会根据函数调用或对象创建的上下文自动推导出模板参数。CTAD的引入简化了模板的使用和书写,使代码更加简洁和易读。需要注意的是,**$CTAD$仅适用于某些特定的上下文和初始化方式,而不是所有情况下都可以省略模板参数**。
为了笔记的简洁性和兼容性,这里依旧使用std::lock_guard作为代码例子。
尽管在某些情况下使用全局变量是合适的,但在大多数情况下,通常将互斥锁和受保护的数据组合在一个类中,而不是使用全局变量。这符合$OOP$的设计规范。但是,有一些眼尖的人会发现,如果一个成员函数返回指向受保护数据的指针或引用,那么所有成员函数都以一种良好、有序的方式锁定互斥锁就无关紧要了,因为你已经在保护中弄出了一个大漏洞。具有对该指针或引用的访问权限的任何代码都可以在不锁定互斥量的情况下访问(并潜在地修改)受保护的数据。因此,用互斥锁保护数据需要仔细的接口设计,以确保互斥锁在对受保护数据进行任何访问之前被锁定,并且没有后门。
Structuring code for protecting shared data
正如你所看到的,使用互斥锁保护共享数据并不是在函数中添加一个std::lock_guard就能解决的简单的事情;一个偏离的指针或引用,就会导致所有的保护工作白费。在一方面来说,检查出偏离的指针或引用是较为容易的;只需要对应的成员函数没有返回所保护数据的指针或引用,或没有通过out参数将其指针或引用传递出去即可。如果你想的更深,就会知道没有什么事情是容易的。除了检查成员函数不会将指针或引用传递给调用者之外,同样重要的是检查它们不会将这些指针或引用传递给它们调用的、不受你控制的函数。因为这些函数可能不会立即使用这些受保护的数据,而是存储起来在没有互斥锁保护的地方去使用。下面就给出了一个例子:
1 | class some_data { |
在这个例子中,process_data看上去是足够安全的,并且很好地被std::lock_guard所保护。但是,这里调用了一个用户提供的函数func,这就意味着它会传递给malicious_function,并且在没有任何保护措施的情况下调用do_something()。
从根本上说,这段代码的问题在于它没有完成你设定的任务:将访问数据结构的所有代码块标记为互斥的。也就是说,它在这个例子中忽略了unprotected->do_something()的保护,更糟糕的是,$c++$标准库对于这一行为并未提供任何保护机制。
因此,不要在互斥锁的范围之外传递指向受保护数据的指针和引用,无论是通过从函数返回它们、将它们存储在外部可见的内存中,还是将它们作为参数传递给用户提供的函数。
Spotting race condition inherent in interface
你现在只是使用互斥锁来保护共享数据,这并不意味着你现在不受竞争条件的影响。你仍然需要确保数据是否受到保护。就以先前的双向链表的删除操作为例,为了使一个线程安全的删除一个节点,我们尝试去将需要被删除的节点和其两边的节点都做出保护措施。但是,这仍旧会发生竞争条件,因为你只是单独的对每一个节点做出了保护,而不是针对于删除操作这整个流程做出保护。在这种情况下,最简单的方式就如之前所示的,使用单个互斥锁将整个链表给保护起来。
但如果只是因为链表上的单个操作受到了保护,那么你还没有真正脱离危险,仍会发生竞争条件。考虑一个栈的数据结构,比如stack适配器。如果你修改了top(),使它返回一个副本而不是一个引用,并且用互斥锁保护内部数据,这个接口仍然会受到竞争条件的影响。这个问题并不是基于互斥锁的实现所独有的,这是一个接口问题,因此在无锁实现中仍然会出现竞争条件。
1 | template < typename T, typename Container = std::deque< T > > |
这里的问题主要是因为empty()和size()的结果不再可靠。尽管在调用时它们可能是正确的,但一旦它们返回,其他线程可以自由访问堆栈,并且在调用empty()或size()的线程使用该信息之前,可能会在堆栈上push()新元素或pop()现有元素。
特别是,如果堆栈实例不是共享的,检查empty()然后调用top()来访问堆栈不为空的top()元素是安全的。
1 | stack< int32_t > s; |
显而易见的,在单线程上这段代码始终是安全的。那么在多线程上,这段代码就不再安全,因为很有可能当前线程位于调用empty()和top()之间时,另一个线程调用了pop()并且移除了栈中的最后一个元素,这将导致未定义行为的产生。因此,在内部使用互斥锁也不能保证行为的正确性。
那么如何解决呢?在最简单的情况下,当栈中没有任何元素时,你可以在top()的实现如果此时被调用,则内部抛出异常。虽然我们直接的解决了这个问题,但是我们又需要在外部捕获这个异常,这显然很冗余。那么针对于empty()调用的优化就有必要了(当然,这并不是必须的)。
如果你细心一点还会发现,在上面的代码片段中,位于top()和pop()之间也存在竞争条件。让我们来考虑这样一种情况,如果你有两个线程同时指向一个栈对象s。假设栈上一开始有两个元素,那么你并不需要担心empty()和top()之间会出现问题。
如果这个栈被互斥锁保护,一次只允许一个线程进入执行其内部函数,那么这些调用就能够正常的交替执行。但是,对于do_something而言,则是并发的。
| Thread A | Thread B |
|---|---|
| if (!e.empty()) | |
| if (!e.empty()) | |
| const int32_t value = s.top() | |
| const int32_t value = s.top() | |
| s.pop() | |
| s.pop() | |
| do_something( value ) | |
| do_something( value ) |
就如你所看到的,如果只有两个线程运行,那么对于top()的调用中间就不会有间隔,因此两个线程中的value看到的是同一份数据。不仅如此,在这两次top()的调用之间,也不会存在pop()的调用。因此,一个值将会在没有被读取的情况下直接被丢弃,而另一个值则会被使用两次。可以看见,这里就是另一个竞争条件存在的位置,并且远比empty()和top()导致的未定义行为阴险的多;更重要的是,这里不会有明显的错误,而且错误的后果和原因还可能取决于do_something()的实际操作。
这需要对接口进行更为激进的改变,即将对top()和pop()的调用在互斥锁的保护下组合起来。但是有人指出,如果栈上对象的复制构造函数可能抛出异常,组合调用可能会导致问题。
我们现在通过stack< vector< int32_t > >来解释这一问题。vector是一个动态大小的容器,因此当你打算拷贝一份vector时,标准库就需要在堆上申请空间以拷贝其数据。如果系统负载过重或存在明显的资源限制,这种内存分配可能失败,因此vector的拷贝构造函数可能抛出std::bad_alloc异常。如果pop()函数的实现为返回被弹出的值,并将其从堆栈中移除时,你就会遇见一个潜在的问题:只有在栈已经被修改之后,弹出的值才会返回给调用者,但在将数据拷贝给调用者的过程中可能会抛出异常。如果这种情况发生,就会导致这个值确实被弹出并移除,但其拷贝却失败了。因此,stack设计该接口的时候,需要将其分为两步:
- 获取栈顶元素(
top()) - 移除该元素(
pop())
因此,如果你不能安全的拷贝这份数据,那么该数据仍会留在栈中。但需要值得注意的是,如果你需要解决竞态的发生,就不应该出现这种分裂的情况。
Option1: Pass In A Reference
解决的第一种方法是:当你想得到弹出的值时,用一个引用作为调用pop()的参数的接收值即可。
1 | std::vector< int32_t > result; |
这在许多情况下都很好用,但它有一个明显的缺点,即要求调用代码在调用前构造一个栈值类型的实例,以便将其作为目标传入。对于某些类型来说,这是不切实际的,因为构造一个实例在时间或资源方面都非常昂贵。对于其他类型来说,这也并非总是可行的,因为构造函数需要的参数在代码的这一点上不一定能够获得。最后,它要求存储的类型是可赋值的。这是一个重要的限制:**许多自定义的类型不支持赋值,尽管它们可能支持移动构造甚至拷贝构造(并允许通过值返回)**。