XV6 Operator System: 04-The Spin Lock
在上一节中,我简单介绍了内核态中的入口函数main()。如果按照入口函数中的初始化顺序,理应讲解consoleinit(),但是位于consoleinit中有涉及到其余部分的介绍,为了每个章节的独立性和可读性,并且为了避免一次性知识的复杂程度过高,这里选择率先讲解spinlock。
在这一节中,我并不打算详细介绍什么是“锁”,只会简单的提一点最为基本的概念以及锁的种类。
锁是一种用于控制多线程或多进程环境中资源访问的同步机制。它的主要作用是防止数据竞争和保持数据一致性。当多个线程或进程需要访问共享资源时,锁可以确保同一时间只有一个线程或进程可以访问该资源,从而避免并发操作带来的问题。
一般而言,常见的锁有:
| 种类 | 用途 |
|---|---|
| 互斥锁(Mutex Lock) | 适用于需要严格防止并发访问的场景,如更新共享变量或文件操作 |
| 读写锁 (Read-Write Lock) | 适用于读多写少的场景,例如缓存系统 |
| 递归锁 (Recursive Lock) | 适用于需要递归调用且每次调用都需要获取同一锁的场景 |
| 自旋锁 (Spin Lock) | 适用于锁持有时间很短的场景,因为自旋锁会消耗 CPU 资源 |
而在xv6-riscv中,我们主要实现的锁便是自旋锁。xv6的目标是尽可能简单地展示操作系统的基本原理。自旋锁的实现相对简单,不需要处理复杂的上下文切换或线程调度问题。实现其他类型的锁(如互斥锁、读写锁)需要更复杂的调度机制和上下文切换管理,这会增加内核的复杂性。而自旋锁只需要简单的检查和自旋等待,不需要操作系统调度线程的切换,简化了内核的实现。
同时,在自旋锁中,由于线程在等待锁的时候不会进行上下文切换,这在某些情况下反而更加高效,特别是在临界区执行时间极短的情况下。避免上下文切换的开销,可以提升系统性能。
Lock
多个$CPU$的xv6共享物理内存,并且利用共享来维护所有$cpu$读取和写入的数据结构。而共享数据则是增加了一个$CPU$在读取数据的同时,另一个$CPU$正在更新该数据结构的可能性,甚至多个$CPU$同时更新。哪怕在单核中,内核也可能不断的在$CPU$中切换大量线程,使得它们交替执行。并发一词指的是由于多处理器并行性、线程切换或中断而导致多条指令流交错的情况。
内核中总是充斥着许多并行数据,内核设计者们为了让内核使用并行以增加其性能和响应性,不得不允许了大量并发的存在。为了不造成严重错误,又设计出并发控制技术来解决这一问题。
这一节主要涉及到并发控制及技术中最为广泛使用的一项技术:锁。锁提供了互斥性,确保了一次只能一个$CPU$享有锁。也就是说,如果一个数据结构使用锁来保护其数据,那么锁就使得一次只有一个$CPU$能够使用该数据。尽管锁是一种极其简单有效的机制,但是大量使用锁会使得性能下降,因为它使其变为了单独的序列化执行。
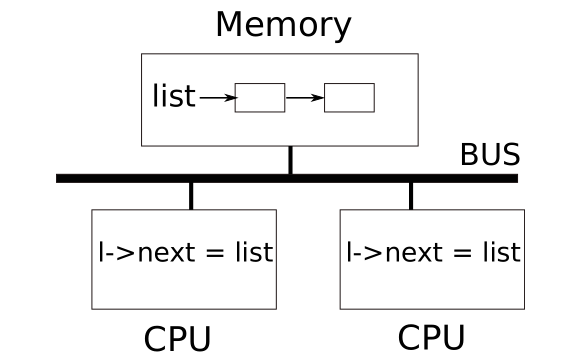
Races
考虑一下这个例子:两个具有退出子进程的进程在两个不同的$CPU$上调用wait,而wait会释放这两个子进程的内存。因此,对于这两个$CPU$而言,内核会调用kfree来回收这两个子进程的内存页。xv6的内核分配器维护了一个链表kalloc(),kalloc会从空闲链表中弹出一页内存,而kfree就会将这页内存给回收。
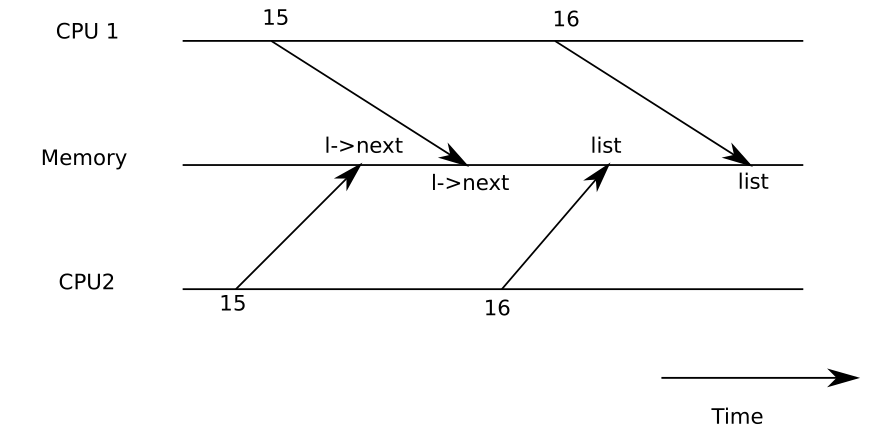
下图展示了一个详细情况:空闲页面的链表位于两个$CPU$的共享内存中,它们使用load和store指令操作该链表:
如果不考虑并发情况,那么你可能会这样实现:
1 | struct element { |
在上面我们说过,如果这段代码是单进程下,那么是正确的。如果两个$CPU$同时执行push,因此这两个$CPU$都可能会在list = l前执行l->next = list。那么就会导致上面图示的结果,两个元素确实插入到链表中,但是第一次对于链表的数据的赋值会发生在第二个节点上,并且第二次的赋值会覆盖掉第一次的赋值,并且第一个节点是没有值的。
这就是竞争的一个简单例子。竞争是一种发生在一块内存被并发访问,并且其中至少有一个操作是写入时的一种状态。竞争的结果取决于编译器生成的机器码、所涉及的两个$cpu$的计时以及它们的内存操作如何由内存系统排序,这可能使竞争引起的错误难以重现和调试。
避免竞争发生的常用方法就是锁。锁的存在保证了互斥性,以至于一次只有一个$cpu$能够执行一些敏感数据:
1 | struct element* list = NULL; |
位于acquire和release之间的代码片段被称为临界区(critical section)。
当我们说锁保护数据时,通常而言是指锁保护应用于数据的一些不变量集合。不变量才是跨操作维护数据结构的属性。换言之,一个操作的是否正确取决于操作时的不变量是否正确。
你可以将锁视为序列化并发临界区,以便它们一次运行一个,从而保留不变量。你还可以将由同一锁保护的临界区视为彼此之间的原子性,因此每个临界区都只能看到来自早期临界区的完整更改集,而永远不会看到部分完成的更新。
内核设计中的一个主要挑战是,在追求并行性时避免锁争用。xv6在这方面做得很少,但复杂的内核会专门组织数据结构和算法以避免锁争用。
Spin Lock’s Code
在xv6种实际上是存在两种锁的,一种则是自旋锁(spin lock),另一种是睡眠锁(sleep lock)。我们首先从自旋锁开始介绍。
在xv6中,自旋锁的结构是在kernel/spinlock.h:2中被定义的:
1 | // Mutual exclusion lock. |
其中,最为主要的一个元素自然是locked,这用于标识是否上锁:当锁可用时,其值为零;锁被拥有时,为非零。
然后我们可以在kernel/spinlock.c中查看其余函数的定义和实现。
initlock
不止在锁这一个模块中,其余每个模块基本上都会存在一个初始化函数,用于在内核进入时统一初始化。
1 | void initlock(struct spinlock *lk, char *name) { |
对于锁的初始化而言,没有过多讲解的必要。这里额外讲解一点$cpu$的结构信息:
1 | // Per-CPU state. |
对于proc和context这两个字段的含义,有些读者可能能够理解,但是目前暂时不需要过多的讲解,因为在此处不会有更多的使用。我们主要了解noff和intena,前者是关于锁嵌套的深度,而后者则是在获取锁之前,该$CPU$的中断使能状态信息。
因此对于锁而言,我们在获取锁后为了避免死锁的发生,需要关闭中断使得获取锁后不会因为中断的发生而导致跳出锁的作用范围。因此,我们就需要率先获取获取锁之前的状态,然后关闭中断使能,后续释放锁后,再根据获取的状态进行恢复使能状态。
对于cpus和mycpu(),则是针对于现代计算机多核的一种设计,我们在处理锁的时候,需要锁住当前$cpu$状态就需要使用。
push_off && pop_off
push_off和pop_off函数的设计和作用主要与中断的管理有关,以确保在持有自旋锁期间不发生上下文切换,从而避免死锁和竞争条件。
push_off函数的主要作用是禁用当前处理器的中断,并记录之前的中断状态。其设计目的是确保在持有自旋锁期间,中断不会打断当前的执行流,从而避免由于中断处理程序尝试获取相同自旋锁而导致的死锁。
1 | void push_off(void) { |
在上面的实现中,intr_get()会获取mstatus寄存器,用于读取当前中断使能状态,然后通过intr_off()关闭中断。当cpu是第一次获取锁时,其中的intena会保存之前的使能状态以供后续恢复。
pop_off函数的主要作用是恢复之前的中断状态。其设计目的是在完成对共享资源的访问后,重新启用中断(如果在获取自旋锁之前中断是启用的)。
1 | void pop_off(void) { |
需要注意的是,解锁的过程中也是处于关中断状态的,因此我们需要判断此时的中断状态以及noff字段。然后通过intena判断是否使用intr_on()恢复中断使能状态。
acquire && release
在xv6中,我们最为常用的两个自旋锁接口是acquire和release。acquire和release函数用于管理自旋锁,它们分别用于获取和释放锁,从而确保对共享资源的互斥访问。
acquire函数用于获取自旋锁。它的主要步骤包括禁用中断、检查当前锁状态、尝试获取锁以及记录当前持有锁的CPU。
1 | void acquire(struct spinlock *lk) { |
我们在上面知道,整个锁的环节都是需要在关中断的状态下完成的,因此关中断肯定是获取锁的第一步。然后我们需要判断该$cpu$是否以及获取过一次锁,如果以及获取锁,那么就会导致错误,因为两个锁的同时拥有会导致问题频发。
1 | int holding(struct spinlock *lk) { |
判断有条件拥有锁后,我们就需要设置locked字段,这里使用了$GCC$提供的内置的原子操作__sync_lock_test_and_set,它是一个$atomic exchange operation$,这样就使得执行交换操作期间不会发生其他线程或进程的干扰,从而保证交换操作是原子的。因此locked就被置为了1,并且其返回值是原先的旧值。因此,如果锁被其他$cpu$所持有,那么就会一直在while中循环直到获取锁,因此被称为自旋锁。
原子交换操作($atomic exchange operation$)
原子交换操作是一种并发编程中的操作,用于在多线程或多进程环境下实现原子性的值交换。它确保在执行交换操作期间不会发生其他线程或进程的干扰,从而保证交换操作是原子的。
在并发环境中,多个线程或进程可以同时访问和修改共享的变量。当多个线程或进程需要同时对某个变量进行读取和写入时,就可能发生竞态条件(race condition),导致不确定的结果或数据不一致的情况。原子交换操作提供了一种解决竞态条件问题的机制。
原子交换操作通常包括两个步骤:读取变量的当前值并将新值写入变量。这两个步骤被视为一个原子操作,要么完全执行成功,要么完全不执行。原子交换操作通常使用底层的硬件指令或操作系统提供的原子操作函数来实现。
然后通过__sync_synchronize内置函数,用于提交一个fence指令进行内存屏障操作。
1 | ; __sync_lock_test_and_set |
AMOSWAP
AMOSWAP指令用于在多线程或多处理器环境下执行原子性的值交换操作。它允许程序原子地读取一个内存位置的当前值,并将一个新值写入该位置。该指令确保在执行交换操作期间不会发生其他线程或处理器的干扰,从而保证交换操作是原子的
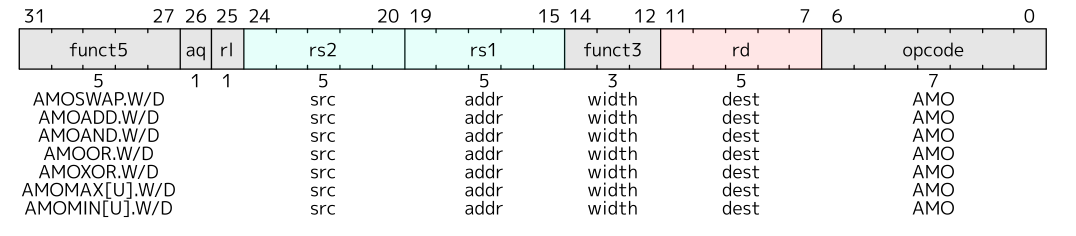
最后,将当前$cpu$的结构信息保存在锁中,用于后续判断和调试。
release函数用于释放自旋锁。它的主要步骤包括检查当前持有锁的$CPU$、清除持有锁的$CPU$信息、释放锁以及恢复中断状态。
1 | void release(struct spinlock *lk) { |
可以看见,首先需要判断的就是当前$cpu$是否含有锁,如果不持有锁,那么release操作肯定就是有问题的。然后我们清空锁持有的$cpu$状态。
在释放锁前,我们需要同步一下$cpu$的状态,因此使用__sync_synchronize提交fence指令。然后通过内建的原子操作__sync_lock_release用于释放通过__sync_lock_test_and_set的设置值。
1 | ; sync_lock_release |
最后,通过pop_off恢复$cpu$的中断使能状态。
至此,关于xv6的自旋锁源码就解释完了。
Deadlock and Lock Ordering
如果内核中的某个代码路径必须同时持有多个锁,那么确保所有代码路径以相同的顺序获取这些锁是非常重要的。如果它们不按照相同的顺序获取锁,就会存在死锁的风险。
假设在xv6操作系统中有两个代码路径需要锁$A$和$B$,但是代码路径1按照$A$然后$B$的顺序获取锁,而另一个代码路径按照$B$然后$A$的顺序获取锁。假设线程T1执行代码路径1并获取了锁$A$,线程T2执行代码路径2并获取了锁$B$。接下来,T1将尝试获取锁$B$,而T2将尝试获取锁$A$。由于在这两种情况下,另一个线程持有所需的锁,并且在其获取返回之前不会释放它,因此两个获取操作都将无限期地阻塞。为了避免这种死锁情况,所有代码路径必须按照相同的顺序获取锁。对于全局锁获取顺序的需求意味着锁实际上是每个函数规范的一部分:调用者必须以一种使得按照约定的顺序获取锁的方式调用函数。
| Lock | Description |
|---|---|
| bcache.lock | 保存块缓冲条目的分配 |
| cons.lock | 序列化对终端硬件的访问,避免混合输出 |
| ftable.lock | 序列化文件表中结构文件的分配 |
| itable.lock | 保护内存中inode条目的分配 |
| vdisk.lock | 序列化对磁盘硬件和DMA描述符队列的访问 |
| kmem.lock | 序列化内存分配 |
| log.lock | 序列化事务日志上的操作 |
| pipe’s pi->lock | 序列化每个管道上的操作 |
| pid_lock | 序列化next_pid的增量 |
| proc’s p->lock | 序列化进程状态的更改 |
| wait_lock | 帮助等待避免丢失唤醒 |
| tickslock | 序列化计时计数器上的操作 |
| inode’s ip->lock | 序列化每个索引节点及其内容上的操作 |
| buf’s b->lock | 序列化每个块缓冲区上的操作 |
出于这种情况,xv6的struct proc有一个chain字段,用于sleep和锁的协同作用。这样就避免了死锁的发生。例如:consoleintr是处理键入字符的中断例程。当输入一个换行符时,任何正在等待控制台输入的进程都应该被唤醒。为了实现这一点,consoleintr在调用wakeup时持有cons.lock,而wakeup会获取等待进程的锁以唤醒它。因此,为了避免全局死锁,锁的获取顺序规则中包括了cons.lock必须在任何进程锁之前获取的规定。文件系统代码包含了xv6中最长的锁链。例如,创建一个文件需要同时持有目录的锁、新文件的inode的锁、磁盘块缓冲区的锁、磁盘驱动器的vdisk_lock以及调用进程的p->lock。为了避免死锁,文件系统代码总是按照前面提到的顺序获取锁。