ArkTS Assembler 在此次的任务中,我们主要是对于riscv64架构下的汇编进行处理,按照之前的经验来看,目前已有的 riscv64汇编代码处理逻辑是依托于 aarch64而来 。因此,在本节中会详细解析两个部分:assembler.h和assembler_aarch64。
Assembler 在这个小节中,我们会聚焦于assembler.h中的关键代码,并且给出后续riscv64可能的方向。
首先,在assembler.h中首先有一个名为GCStackMapRegisters的类,在ArkTS中,存在GC机制。因此,这里的GCStackMapRegisters可能是用于垃圾回收机制中的栈映射寄存器。在垃圾回收算法中,栈映射寄存器用于记录程序执行过程中的栈帧信息,以便正确地识别和回收不再使用的对象。栈映射寄存器通常用于确定每个栈帧的边界和对象引用的位置。通过分析栈映射寄存器中的值,垃圾回收器可以构建出程序的栈帧结构,识别出栈中的对象引用,并进行相应的垃圾回收操作 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class GCStackMapRegisters {public :#if defined(PANDA_TARGET_AMD64) static constexpr int SP = 7 ; static constexpr int FP = 6 ; #elif defined(PANDA_TARGET_ARM64) static constexpr int SP = 31 ; static constexpr int FP = 29 ; #elif defined(PANDA_TARGET_ARM32) static constexpr int SP = 13 ; static constexpr int FP = 11 ; #elif defined(PANDA_TARGET_RISCV64) static constexpr int SP = 2 ; static constexpr int FP = 8 ; #else static constexpr int SP = -1 ; static constexpr int FP = -1 ; #endif
而在该内中的存在两个尚未完全的函数GetFpRegByTriple和GetSpRegByTriple,因为这两个函数中均未对RISCV64进行实现,因此可能在后续实现中,需要对其进行补全。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static int GetFpRegByTriple (Triple triple) int fp = -1 ; switch (triple) { case Triple::TRIPLE_AMD64: fp = 6 ; break ; case Triple::TRIPLE_ARM32: fp = 11 ; break ; case Triple::TRIPLE_AARCH64: fp = 29 ; break ; default : UNREACHABLE (); break ; } return fp; }
而GetFpRegByTriple和GetSpRegByTriple唯一一次被调用则是位于ecmascript/stackmap/llvm_stackmap_type.cpp中。至于具体作用,如果后续需要则会继续分析。
1 2 auto fpReg = GCStackMapRegisters::GetFpRegByTriple (triple);auto spReg = GCStackMapRegisters::GetSpRegByTriple (triple);
继续往下看,则会看见一段异常重要的代码FrameCompletionPos,(根据自己的猜测 )用于表示从C++代码到汇编代码的转换和从汇编代码返回到C++代码时的指令数量 。
1 2 3 4 5 6 7 8 9 10 11 12 enum FrameCompletionPos : uint64_t { X64CppToAsmInterp = 28 , X64AsmInterpToCpp = 9 , X64EntryFrameDuration = 70 , ARM64CppToAsmInterp = 56 , ARM64AsmInterpToCpp = 40 , ARM64EntryFrameDuration = 116 , RISCV64EntryFrameDuration = 140 , };
对于X64(x86-64)体系结构:
X64CppToAsmInterp 表示从C++代码转换到汇编代码时的指令数量为 28。 X64AsmInterpToCpp 表示从汇编代码返回到C++代码时的指令数量为 9。 X64EntryFrameDuration 表示使用汇编解释器(AsmInterpreterEntryFrame)时的汇编帧的指令数量为 70。
对于ARM64(ARM64)体系结构:
ARM64CppToAsmInterp 表示从C++代码转换到汇编代码时的指令数量为 56。 ARM64AsmInterpToCpp 表示从汇编代码返回到C++代码时的指令数量为 40。 ARM64EntryFrameDuration 表示使用汇编解释器时的汇编帧的指令数量为 116。
对于RISCV64(RISC-V64)体系结构:
RISCV64EntryFrameDuration 表示使用汇编解释器时的汇编帧的指令数量为 140。
这里的代码实际上在我们处理RISC-V64 Assembler时没有影响,而是会在另外一个极其重要、并且需要我们处理的模块stub trapoline中进行使用,这里不做过多介绍:
1 if ((end - begin) != FrameCompletionPos::RISCV64EntryFrameDuration)
Label 在这个部分中,主要介绍用于处理汇编逻辑中的跳转指令的标签 。在ArkTS的运行时中使用一个名为Label的类进行标识:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Label {public : bool IsBound () const bool IsLinked () const bool IsLinkedNear () const uint32_t GetPos () const uint32_t GetLinkedPos () const void BindTo (int32_t pos) void LinkTo (int32_t pos) void UnlinkNearPos () void LinkNearPos (uint32_t pos) uint32_t GetLinkedNearPos () const private : int32_t pos_ = 0 ; uint32_t nearPos_ = 0 ; };
首先我们需要区分两个概念:绑定(bound)和链接(link)。在ArkTS中,绑定和链接是两个相似,但行为不同的操作:
bound指的是将标签绑定到特定的位置。绑定标签意味着将标签与某个位置相关联,通常用于表示位于后面的标签 。link指的是将标签链接到特定的位置。链接标签意味着将标签与某个位置相关联,通常用于表示位于前面的标签 。
这里我们可以使用实际的汇编代码进行解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ; 绑定标签示例 section .text global _start _start: ; 链接的位置 ; 绑定标签到位置 jmp bind_label bind_label: ; 这里是绑定的位置 ; ... jmp _start ; 链接回起始位置 ; 继续执行其他代码...
现在来解释各个函数的作用:
IsBound() 函数用于检查标签是否已绑定。如果 $pos_ \gt 0$,则表示标签已绑定。IsLinked() 函数用于检查标签是否已链接。如果 $pos_ \lt 0$,则表示标签已链接。 IsLinkedNear() 函数用于检查标签是否已链接至近跳转位置。如果 $nearPos_ \gt 0$,则表示标签已链接至近跳转位置。 GetPos() 函数用于获取标签的位置。返回 $pos_ - 1$ 的无符号整数值。 GetLinkedPos() 函数用于获取链接的位置。如果标签未绑定,则返回 $-pos_ - 1$ 的无符号整数值。 BindTo() 函数将标签绑定到给定的位置。将 pos_ 设置为 $pos + 1$,以跳过偏移为 0 的位置。 LinkTo() 函数将标签链接到给定的位置。将 pos_ 设置为 $-(pos + 1)$,以跳过偏移为 0 的位置。 UnlinkNearPos() 函数取消链接至近跳转位置。 LinkNearPos() 函数将标签链接至近跳转位置。将 nearPos_ 设置为 $pos + 1$,以跳过偏移为 0 的位置。 GetLinkedNearPos() 函数用于获取链接至近跳转位置的位置。如果标签未绑定,则返回 $nearPos_ - 1$ 的无符号整数值。
Assembler 接下来则是整个assembler.h中最为重要的模块,所有架构的汇编处理逻辑都需要继承于Assembler。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Assembler {public : explicit Assembler (Chunk *chunk) : buffer_(chunk) { } ~Assembler () = default ; void EmitU8 (uint8_t v) void EmitI8 (int8_t v) void EmitU16 (uint16_t v) void EmitU32 (uint32_t v) void EmitI32 (int32_t v) void EmitU64 (uint64_t v) void PutI8 (size_t offset, int8_t data) void PutI32 (size_t offset, int32_t data) uint32_t GetU32 (size_t offset) const int8_t GetI8 (size_t offset) const uint8_t GetU8 (size_t offset) const size_t GetCurrentPosition () const uint8_t *GetBegin () const static bool InRangeN (int32_t x, uint32_t n) static bool InRange8 (int32_t x) static void GetFrameCompletionPos (uint64_t &headerSize, uint64_t &tailSize, uint64_t &entryDuration) private : DynChunk buffer_; };
在Assembler中,buffer_用于存储汇编的机器码 ,而Emit*则是会调用buffer_.Emit*进行处理逻辑,这样能够根据汇编的机器码依次正确地存入内存中,以便后续处理。
比如:在X64架构中的Assembler::Addq,其要处理的汇编为:REX.W + 03 /r。这里需要注意的是,你应该知晓x64架构下汇编的格式为:
因此,首先我们需要处理Instruction Prefixes,然后处理Opcode,最后处理ModR/M。因为这里不需要处理SIB。我们重新看回REX.W + 03 /r,其中REX.W是Instruction Prefixes,03是Opcode,而/r则是ModR/M。而每一个段在此处都是一个字节,因此:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void AssemblerX64::Addq (Register src, Register dst) EmitRexPrefix (dst, src); EmitU8 (0x03 ); EmitModrm (dst, src); } void EmitRexPrefix (Register reg, Register rm) EmitU8 (REX_PREFIX_W | (HighBit (reg) << 2 ) | HighBit (rm)); } void EmitModrm (int32_t reg, Register rm) EmitU8 (MODE_RM | (static_cast <uint32_t >(reg) << LOW_BITS_SIZE) | LowBits (rm)); }
至此,我们能够看见,Assembler中的任何处理逻辑,都是依托于其真实汇编的机器码逻辑,并且根据其真实字节位宽进行处理,就比如EmitU8则是填入uint8_t。
至于Put*,此处不做过多介绍,其实际内部逻辑也是进行填入操作,但是会直接通过偏移量进行填入,需要我们自行保证其边界问题和内存安全问题。
1 2 3 4 5 inline void PutU32 (size_t offset, uint32_t data) const *reinterpret_cast <uint32_t *>(buf_ + offset) = data; }
Aarch64 Assembler Detail 这一个小节主要是介绍aarch64架构下的汇编处理逻辑,因为RISC-V64架构大部分逻辑是临摹aarch64架构所写,因此分析aarch64的完整逻辑对后续开发有很大帮助。
Register 处理一个汇编首先需要解决的问题是,如何处理对应架构汇编下的对应寄存器 。在aarch64中有两组寄存器:通用寄存器和SIMD寄存器。
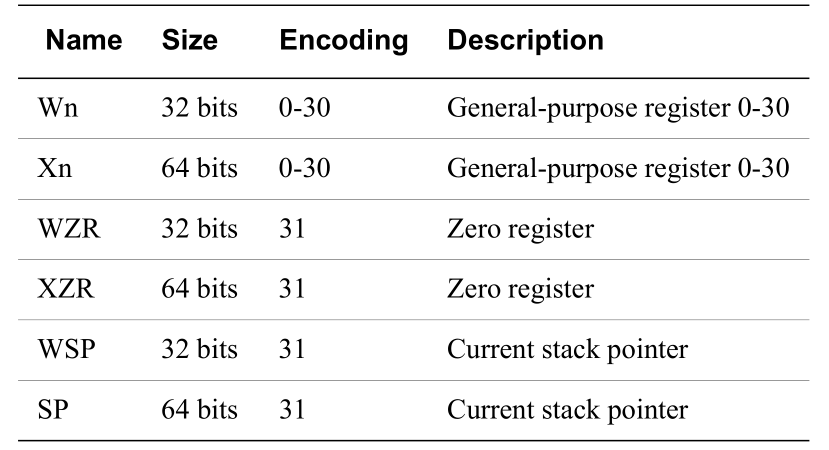
General Purpose Register 通用寄存器中的$31$个通用寄存器被命名为$R_0-R_{30}$,并在指令寄存器字段中以值$0-30$进行编码。在通用寄存器字段中,值$31$表示当前的堆栈指针或零寄存器 ,具体取决于指令和操作数位置。
对于上图所给出的寄存器,这里有几个点需要注意的:
$X_n$和$W_n$实际上指向的是同一组寄存器$R_n$,其只有位宽的差距;当然$WSP$和$SP$也是类似的情况。
没有名为$W_{31}$或$X_{31}$的寄存器,使用$WZR$或$XZR$来表示第$31$号的零寄存器,当读写该寄存器时,其表现为返回零值或抛弃写入值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 enum RegisterId : uint8_t { X0, X1, X2, X3, X4, X5, X6, X7, X8, X9, X10, X11, X12, X13, X14, X15, X16, X17, X18, X19, X20, X21, X22, X23, X24, X25, X26, X27, X28, X29, X30, SP, Zero = SP, FP = X29, INVALID_REG = 0xFF , }; enum RegisterType { W = 0 , X = 1 , }; static const int RegXSize = 64 ;static const int RegWSize = 32 ;
值得注意的是,在arm中$SP = 31,ZERO = 31,FP = 29$。
General Condition
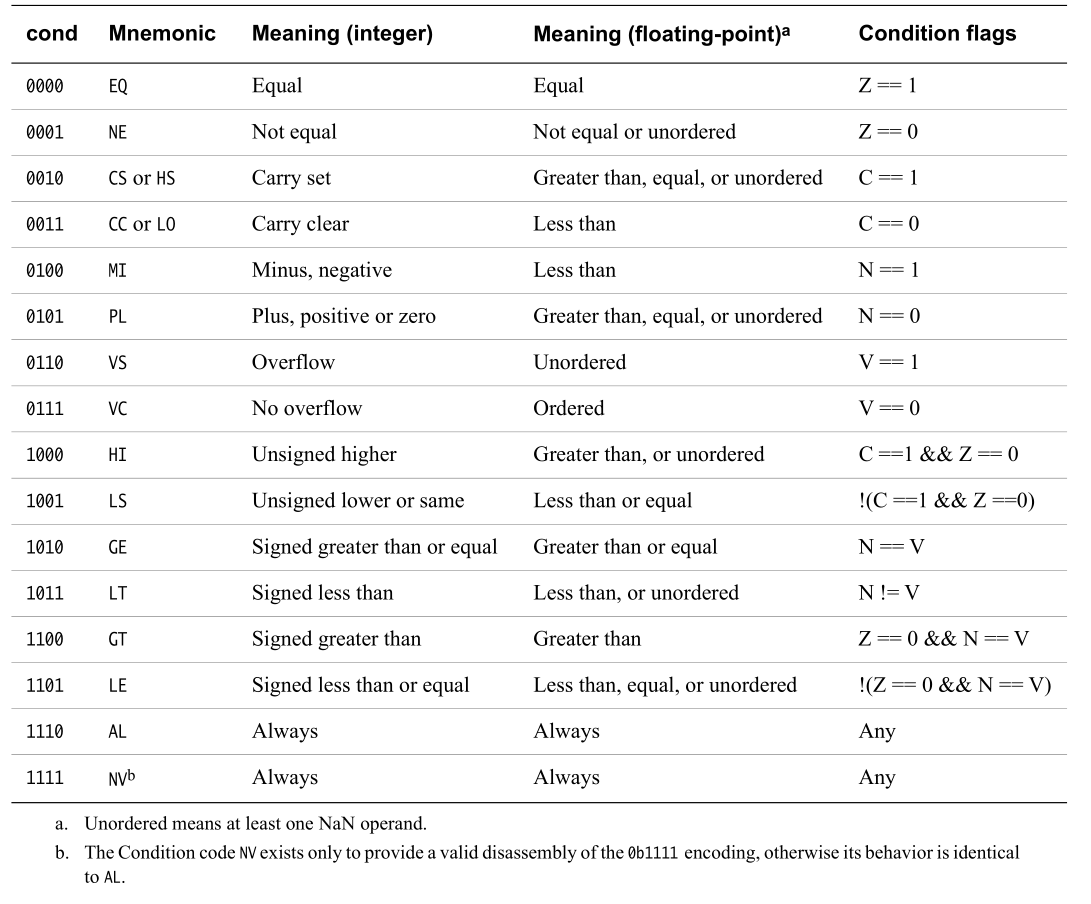
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 enum Condition { EQ = 0 , NE = 1 , HS = 2 , CS = HS, LO = 3 , CC = LO, MI = 4 , PL = 5 , VS = 6 , VC = 7 , HI = 8 , LS = 9 , GE = 10 , LT = 11 , GT = 12 , LE = 13 , AL = 14 , NV = 15 , };
Register Code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Register {public : Register (RegisterId reg, RegisterType type = RegisterType::X) : reg_ (reg), type_ (type) {}; Register W () const ; Register X () const ; RegisterType GetType () const ; inline RegisterId GetId () const inline bool IsSp () const inline bool IsW () const inline bool IsValid () const inline bool operator !=(const Register &other); inline bool operator ==(const Register &other); private : RegisterId reg_; RegisterType type_; };
这里不需要过多的解释,根据上面的所有信息就能够自然的构建出这样的一个Register类型。
SIMD Register 在aarch下的SIMD寄存器总共有$32$个,$V_0 - V_{31}$,其用于保存标量(scalar)浮点指令的浮点操作数以及SIMD指令的标量(scalar)和矢量(vector)操作数 。
当它们以特定的指令形式使用时,必须进一步限定名称以指示数据形状,即数据元素大小和寄存器内元素或通道的数量 。数据类型由对数据进行操作的指令助记符描述。数据类型不是由寄存器名描述的。数据类型是对每个寄存器或向量元素中的位的解释,无论这些是整数、浮点值、多项式还是加密哈希。
上图中的左图表示了SIMD的标量寄存器名,其指定了操作标量数据时只访问高级SIMD和浮点寄存器的低位。未使用的高位在读取时会被忽略,在写入时会被清零 。
而右图表示向量寄存器名,在一开始我们就说过:必须进一步限定名称以指示数据形状 ,也就是说,这里就给出了向量寄存器的数据形状,即数据元素大小和内部通道的数量。其中$V_n$在$V_0 - V_31$中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum VectorRegisterId : uint8_t { v0, v1, v2, v3, v4, v5, v6, v7, v8, v9, v10, v11, v12, v13, v14, v15, v16, v17, v18, v19, v20, v21, v22, v23, v24, v25, v26, v27, v28, v29, v30, v31, INVALID_VREG = 0xFF , }; enum Scale { B = 0 , H = 1 , S = 2 , D = 3 , Q = 4 , };
SIMD Code 1 2 3 4 5 6 7 8 9 10 11 12 13 class VectorRegister {public : explicit VectorRegister (VectorRegisterId reg, Scale scale = D) : reg_(reg), scale_(scale) { inline VectorRegisterId GetId () const inline bool IsValid () const inline Scale GetScale () const inline int GetRegSize () const private : VectorRegisterId reg_; Scale scale_; };
Operand 在aarch中,Operand的类型可以大致分为两类:Data Processing和Load and Store。为了处理这两种类型,我们在实际代码编写中需要构建两个类:Operand和MemoryOperand。其中,这两个类会由Register、Immediate、Extend、Shift和AddrMode分别构成。
对于Register类型这里就不再赘述,其主要管理了寄存器的编号和类型 ,如果是向量寄存器,则会额外管理标量(scalar)。
对于Immediate类型而言,只是一个最为简单的数据封装,分为Immediate和LogicImmediate:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Immediate {public : Immediate (int64_t value) : value_ (value) {} ~Immediate () = default ; int64_t Value () const private : int64_t value_; }; class LogicalImmediate {public : static LogicalImmediate Create (uint64_t imm, int width) int Value () const bool IsValid () const bool Is64bit () const private : explicit LogicalImmediate (int value) : imm_(value) { } static const int InvalidLogicalImmediate = -1 ; int imm_; };
而Extend则是作为Immediate的扩展类型指导,用于标记是否需要进行立即数扩展和以哪一种方式进行扩展 。
1 2 3 4 5 6 7 8 9 10 11 enum Extend : uint8_t { NO_EXTEND = 0xFF , UXTB = 0 , UXTH = 1 , UXTW = 2 , UXTX = 3 , SXTB = 4 , SXTH = 5 , SXTW = 6 , SXTX = 7 , };
对于Shift,是作为对应了位移和旋转操作(逻辑位移、算数位移、旋转以及条件性移动指令):
1 2 3 4 5 6 7 8 enum Shift : uint8_t { NO_SHIFT = 0xFF , LSL = 0x0 , LSR = 0x1 , ASR = 0x2 , ROR = 0x3 , MSL = 0x4 , };
对于AddrMode来说,用于内存访问指令的寻址模式 。
1 2 3 4 5 enum AddrMode { OFFSET, PREINDEX, POSTINDEX };
OFFSET:仅计算偏移量,但不更新基地址寄存器。PREINDEX:在访问之前计算偏移量并更新基地址寄存器。POSTINDEX:在访问之后计算偏移量并更新基地址寄存器。
1 2 3 4 5 6 ; OFFSET LDR X0, [X1, #8] ; 从地址 X1 + 8 处加载数据到 X0 寄存器 ; PREINDEX LDR X0, [X1, #8]! ; 从地址 X1 + 8 处加载数据到 X0 寄存器,并更新 X1 为 X1 + 8 ; POSTINDEX LDR X0, [X1], #8 ; 从地址 X1 处加载数据到 X0 寄存器,并在加载后将 X1 更新为 X1 + 8
由这些组合而成的Operand能够为之后Assembler提供相应的操作数,这样能够避免过多冗余数据的产生。
Data Operand 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Operand {public : Operand (Immediate imm) : reg_ (RegisterId::INVALID_REG), extend_ (Extend::NO_EXTEND), shift_ (Shift::NO_SHIFT), shiftAmount_ (0 ), immediate_ (imm) {} Operand (Register reg, Shift shift = Shift::LSL, uint8_t shift_amount = 0 ) : reg_ (reg), extend_ (Extend::NO_EXTEND), shift_ (shift), shiftAmount_ (shift_amount), immediate_ (0 ) {} Operand (Register reg, Extend extend, uint8_t shiftAmount = 0 ) : reg_ (reg), extend_ (extend), shift_ (Shift::NO_SHIFT), shiftAmount_ (shiftAmount), immediate_ (0 ) {} ~Operand () = default ; inline bool IsImmediate () const inline bool IsShifted () const inline bool IsExtended () const inline Register Reg () const inline Shift GetShiftOption () const inline Extend GetExtendOption () const inline uint8_t GetShiftAmount () const inline int64_t ImmediateValue () const inline Immediate GetImmediate () const private : Register reg_; Extend extend_; Shift shift_; uint8_t shiftAmount_; Immediate immediate_; };
Memory Operand 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class MemoryOperand {public : MemoryOperand (Register base, Register offset, Extend extend, uint8_t shiftAmount = 0 ) : base_ (base), offsetReg_ (offset), offsetImm_ (0 ), addrmod_ (AddrMode::OFFSET), extend_ (extend), shift_ (Shift::NO_SHIFT), shiftAmount_ (shiftAmount) {} MemoryOperand (Register base, Register offset, Shift shift = Shift::NO_SHIFT, uint8_t shiftAmount = 0 ) : base_ (base), offsetReg_ (offset), offsetImm_ (0 ), addrmod_ (AddrMode::OFFSET), extend_ (Extend::NO_EXTEND), shift_ (shift), shiftAmount_ (shiftAmount) {} MemoryOperand (Register base, int64_t offset, AddrMode addrmod = AddrMode::OFFSET) : base_ (base), offsetReg_ (RegisterId::INVALID_REG), offsetImm_ (offset), addrmod_ (addrmod), extend_ (Extend::NO_EXTEND), shift_ (Shift::NO_SHIFT), shiftAmount_ (0 ) {} ~MemoryOperand () = default ; Register GetRegBase () const ; bool IsImmediateOffset () const Immediate GetImmediate () const ; AddrMode GetAddrMode () const ; Extend GetExtendOption () const ; Shift GetShiftOption () const ; uint8_t GetShiftAmount () const Register GetRegisterOffset () const ; private : Register base_; Register offsetReg_; Immediate offsetImm_; AddrMode addrmod_; Extend extend_; Shift shift_; uint8_t shiftAmount_; };
这里与Operand不同的是,因为aarch64是以基址作为跳转的,因此我们需要一个基址寄存器和一个偏移量(这个偏移量可能是寄存器值也可能是立即数值)。还需要通过AddrMode来判断具体的寻址模式。
Assembler Implement 在前面讲解assembler.h时,我有提到:所有的实际架构的汇编都是基于Assembler的,因此,我们实际上是要对buffer_进行操作,对数据进行处理后,写入实际的汇编对应的机器码 。
1 class AssemblerAarch64 : public Assembler;
这里还需要注意一点,在ArkTS实现aarch64时,使用了宏来确定了指令集的字段、位宽和掩码等数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #define DECL_FIELDS_IN_INSTRUCTION(INSTNAME, FIELD_NAME, HIGHBITS, LOWBITS) \ static const uint32_t INSTNAME##_##FIELD_NAME##_HIGHBITS = HIGHBITS; \ static const uint32_t INSTNAME##_##FIELD_NAME##_LOWBITS = LOWBITS; \ static const uint32_t INSTNAME##_##FIELD_NAME##_WIDTH = ((HIGHBITS - LOWBITS) + 1); \ static const uint32_t INSTNAME##_##FIELD_NAME##_MASK = (((1 << INSTNAME##_##FIELD_NAME##_WIDTH) - 1) << LOWBITS); #define DECL_INSTRUCTION_FIELDS(V) \ COMMON_REGISTER_FIELD_LIST(V) \ LDP_AND_STP_FIELD_LIST(V) \ LDR_AND_STR_FIELD_LIST(V) \ MOV_WIDE_FIELD_LIST(V) \ BITWISE_OP_FIELD_LIST(V) \ ADD_SUB_FIELD_LIST(V) \ COMPARE_OP_FIELD_LIST(V) \ BRANCH_FIELD_LIST(V) \ BRK_FIELD_LIST(V) #define COMMON_REGISTER_FIELD_LIST(V) \ V(COMMON_REG, Rd, 4, 0) \ V(COMMON_REG, Rn, 9, 5) \ V(COMMON_REG, Rm, 20, 16) \ V(COMMON_REG, Rt, 4, 0) \ V(COMMON_REG, Rt2, 14, 10) \ V(COMMON_REG, Sf, 31, 31)
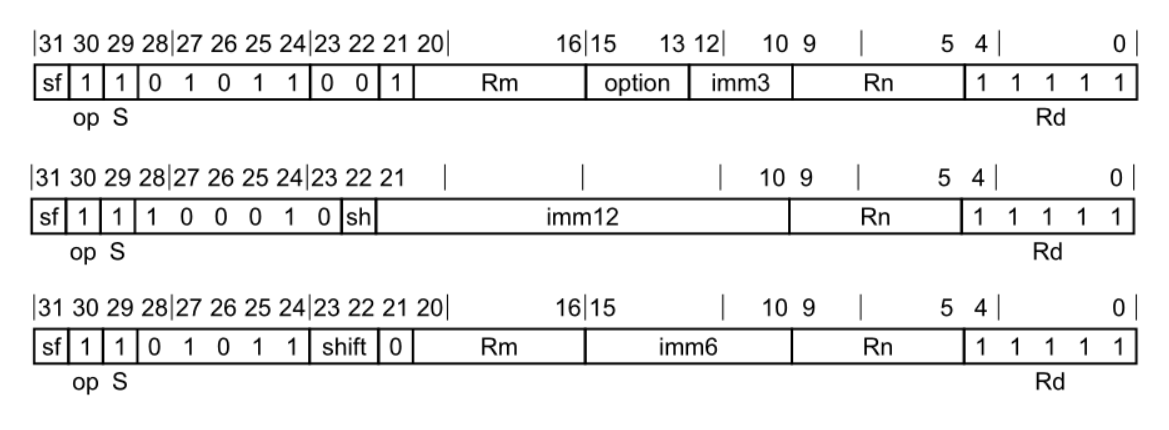
Add && Sub 在aarch64中,add和sub是一组几乎相同的指令。因此我们主要针对add进行讲解。add有两种类型:add和adds(我们不考虑addg的实现)。其中,add和adds各有三种情况:extend register、immediate和shifted register。
add(extend register) Add(extended register)指令将一个寄存器值和一个符号或零扩展的寄存器值相加,并可以选择进行左移,然后将结果写入目标寄存器 。由<Rm>寄存器扩展而来的参数可以是字节(byte)、半字(halfword)、字(word)或双字(doubleword)。
从sf位可以判断指令的数据位宽:
如果$sf = 0$,则表示$32bits$:
ADD <Wd|WSP>, <Wn|WSP>, <Wm>{, <extend> {#<amount>}}
如果$sf = 1$,则表示$64bits$:
ADD <Xd|SP>, <Xn|SP>, <R><m>{, <extend> {#<amount>}}
对于*d而言,则为作为目的寄存器,而*n是第一个源寄存器。而*m自然就是第二个源寄存器。对于在$64bits$下的指令格式而言,<R>用于表示寄存器前缀,<m>表示其寄存器号:
<R>code
W
option = 00x
W
option = 010
X
option = x11
W
option = 10x
W
option = 110
对于<extend>而言,则是和Extend这一实现有关,如果有需要请自行向上检索Extend或查阅相关手册。
如果Rd或Rn寄存器为$11111$即WSP时,当指令为$32bits$时,且$option = 010$,则以LSL作为扩展方式;如果为$64bits$,且$option = 011$,则以LSL作为扩展方式。但如果$imm3 = 000$时,其可以被省略,否则其他情况下<extend>是必须的;且在$option = 010$时($32bits$),还需以UXTW方式扩展;在$option = 011$时(64bits),以UXTW方式扩展。
<amount>与imm3字段有关,其用于左移的适当的偏移量,范围在$0 - 4$中(默认为$0$)。如果<extend>字段不存在,那么<amount>也就不存在;如果<extend>为LSL,那么<amount>就必须存在;如果<extend>存在但不为LSL,那么<amount>就是一个可选择的选项。
add(immediate)添加一个寄存器值和一个可选择性位移的立即数值,并写入到目的寄存器中。该指令可以用于MOV(to/from SP)的别名。
1 2 ADD <Wd|WSP>, <Wn|WSP>, #<imm>{, <shift>} ; 32-bits ADD <Xd|SP>, <Xn|SP>, #<imm>{, <shift>} ; 64-bits
当$sh = 0$且$imm12 = 0$,以及$R_n = SP$和$R_d = SP$时,可以用作MOV的一个别名:
对于之前相同的字段名,这里不做过多介绍。imm12和imm3类似,不过这里的imm12是立即数数据,用于计算,其范围在$0 - 4095$之间。
对于<shift>字段,则是会默认对<imm12>字段进行LSL #0的操作。如果$sh = 1$,则会进行LSL #12的操作(即符号扩展)。
1 2 3 case sh of when '0' imm = ZeroExtend (imm12, datasize); when '1' imm = ZeroExtend (imm12:Zeros (12 ), datasize);
add(shifted register) add(shifted register)添加一个寄存器值和一个可选择性位移的寄存器值,并写入到目的寄存器中。
1 2 ADD <Wd>, <Wn>, <Wm>{, <shift> #<amount>} ; 32-bits ADD <Xd>, <Xn>, <Xm>{, <shift> #<amount>} ; 64-bits
对于<shift>字段,其会对第二个源寄存器进行处理:
type
code
LSL
shift = 00
LSR
shift = 01
ASR
shift = 10
而<amount>字段则是与imm6字段相关,用于位移的位宽,其范围为$0 - 31$,默认为$0$。
adds 对于adds指令而言,也有三种情况:adds(extended register)、adds(immediate)和adds(shifted register)。与上面的add不同的只有其中的<S>标志,以及执行加法操作,同时更新条件标志 ($N$, $Z$, $C$, $V$)。其余均无变化。
1 2 3 4 5 6 7 8 9 10 11 ; adds(extend register) ADDS <Wd>, <Wn|WSP>, <Wm>{, <extend> {#<amount>}} ; 32-bits ADDS <Xd>, <Xn|SP>, <R><m>{, <extend> {#<amount>}} ; 64-bits ; adds(immediate) ADDS <Wd>, <Wn|WSP>, #<imm>{, <shift>} ADDS <Xd>, <Xn|SP>, #<imm>{, <shift>} ; adds(shifted register) ADDS <Wd>, <Wn>, <Wm>{, <shift> #<amount>} ADDS <Xd>, <Xn>, <Xm>{, <shift> #<amount>}
condition
meaning
N(Negative)
$result \lt 0$
Z(Zero)
$result = 0$
C(Carry)
carry
V(Overflow)
over flow
还有一点差距的是:
adds(extended register)可用作CMN(extended register)的别名adds(immediate)可用作CMN(immediate)的别名adds(shifted register)可用作CMN(shifted register)的别名
add code 首先,我们通过上面所说的宏定义,给出add指令集对应的字段和位宽。
1 2 3 4 5 6 7 8 #define ADD_SUB_FIELD_LIST(V) \ V(ADD_SUB, S, 29, 29) \ V(ADD_SUB, Sh, 22, 22) \ V(ADD_SUB, Imm12, 21, 10) \ V(ADD_SUB, Shift, 23, 22) \ V(ADD_SUB, ShiftAmount, 15, 10) \ V(ADD_SUB, ExtendOption, 15, 13) \ V(ADD_SUB, ExtendShift, 12, 10)
因为add和sub这两个指令集相差无几,所以我们将这两个指令集的字段和处理逻辑同放在AddSubImm和AddSubReg中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void AssemblerAarch64::AddSubImm (AddSubOpCode op, const Register &rd, const Register &rn, bool setFlags, uint64_t imm) ASSERT (IsAddSubImm (imm)); uint32_t shift = 0 ; const uint64_t IMM12_MASK = (1 << ADD_SUB_Imm12_WIDTH) - 1 ; uint64_t imm12 = imm & (~IMM12_MASK); if (imm12 != 0 ) { shift = 1 ; } else { imm12 = imm; } uint32_t flags_field = ((setFlags ? 1 : 0 ) << ADD_SUB_S_LOWBITS) & ADD_SUB_S_MASK; uint32_t imm_field = (imm12 << ADD_SUB_Imm12_LOWBITS) & ADD_SUB_Imm12_MASK; uint32_t shift_field = (shift << ADD_SUB_Sh_LOWBITS) & ADD_SUB_Sh_MASK; uint32_t code = Sf (!rd.IsW ()) | op | flags_field | shift_field | imm_field | Rd (rd.GetId ()) | Rn (rn.GetId ()); EmitU32 (code); }
对于add(immediate)的处理而言,我们需要对是否需要进行扩展和立即数进行提取,然后移动到对应的位上即可。setFlags用于判断是add还是adds。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void AssemblerAarch64::AddSubReg (AddSubOpCode op, const Register &rd, const Register &rn, bool setFlags, const Operand &operand) uint32_t flags_field = ((setFlags ? 1 : 0 ) << ADD_SUB_S_LOWBITS) & ADD_SUB_S_MASK; uint32_t code = 0 ; if (operand.IsShifted ()) { uint32_t shift_field = ((operand.GetShiftOption ()) << ADD_SUB_Shift_LOWBITS) & ADD_SUB_Shift_MASK; uint32_t shift_amount = ((operand.GetShiftAmount ()) << ADD_SUB_ShiftAmount_LOWBITS) & ADD_SUB_ShiftAmount_MASK; ASSERT ((op == ADD_Shift) | (op == SUB_Shift)); code = Sf (!rd.IsW ()) | op | flags_field | shift_field | Rm (operand.Reg ().GetId ()) | shift_amount | Rn (rn.GetId ()) | Rd (rd.GetId ()); } else { ASSERT ((op == ADD_Extend) | (op == SUB_Extend)); uint32_t extend_field = (operand.GetExtendOption () << ADD_SUB_ExtendOption_LOWBITS) & ADD_SUB_ExtendOption_MASK; uint32_t extend_shift = (operand.GetShiftAmount () << ADD_SUB_ExtendShift_LOWBITS) & ADD_SUB_ExtendShift_MASK; code = Sf (!rd.IsW ()) | op | flags_field | Rm (operand.Reg ().GetId ()) | extend_field | extend_shift | Rn (rn.GetId ()) | Rd (rd.GetId ()); } EmitU32 (code); }
这里同时处理了add(extend register)和add(shifted register)这两种情况,可以看见,实际上就是将对应字段数据处理到真实机器码字段的对应位置即可。
CMP cmp 在aarch64中,CMP有三种类型,其都可以与SUBS等价。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ; cmp(extend register) CMP <Wn|WSP>, <Wm>{, <extend> {#<amount>}} ; 32-bits equals SUBS WZR, <Wn|WSP>, <Wm>{, <extend> {#<amount>}} CMP <Xn|SP>, <R><m>{, <extend> {#<amount>}} ; 64-bits equals SUBS XZR, <Xn|SP>, <R><m>{, <extend> {#<amount>}} ; cmp(immediate) CMP <Wn|WSP>, #<imm>{, <shift>} ; 32-bits equals SUBS WZR, <Wn|WSP>, #<imm> {, <shift>} CMP <Xn|SP>, #<imm>{, <shift>} ; 64-bits equals SUBS XZR, <Xn|SP>, #<imm> {, <shift>} ; cmp(shifted register) CMP <Wn>, <Wm>{, <shift> #<amount>} ; 32-bits equals SUBS WZR, <Wn>, <Wm> {, <shift> #<amount>} CMP <Xn>, <Xm>{, <shift> #<amount>} ; 64-bits equals SUBS XZR, <Xn>, <Xm> {, <shift> #<amount>}
CBZ CBZ将寄存器中的值与零进行比较,如果比较结果相等,则条件跳转到一个与当前程序计数器(PC)相对偏移的标签处。该指令提示这不是一个子程序调用或返回。这条指令不会影响条件标志 。
1 2 CBZ <Wt>, <label> ; 32-bits CBZ <Xt>, <label> ; 64-bits
对于CBZ而言,最简单的实现就是直接跳转到立即数地址处,但是我们为了更加方便,还增加了一个Label的重载,通过Label计算其偏移量,然后进行跳转:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void AssemblerAarch64::Cbz (const Register &rt, Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; Cbz (rt, offsetImm); } void AssemblerAarch64::Cbz (const Register &rt, int32_t imm) uint32_t code = Sf (!rt.IsW ()) | BranchOpCode::CBZ | BranchImm19 (imm) | rt.GetId (); EmitU32 (code); }
CBNZ CBNZ将寄存器中的值与零进行比较,如果比较结果不相等,则条件跳转到一个与当前程序计数器(PC)相对偏移的标签处。该指令提示这不是一个子程序调用或返回。这条指令不会影响条件标志 。
1 2 CBNZ <Wt>, <label> ; 32-bits CBNZ <Xt>, <label> ; 64-bits
CBNZ的代码实现和CBZ几乎相同:
1 2 3 4 5 6 7 8 9 10 11 12 13 void AssemblerAarch64::Cbnz (const Register &rt, Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; Cbnz (rt, offsetImm); } void AssemblerAarch64::Cbnz (const Register &rt, int32_t imm) uint32_t code = Sf (!rt.IsW ()) | BranchOpCode::CBNZ | BranchImm19 (imm) | rt.GetId (); EmitU32 (code); }
Branch B B会引起一个无条件跳转到一个与程序计数器(PC)相对偏移的标签,并提示这不是一个子程序调用或返回 。
为了支持度更高,我们也和CMP一样,针对Label做了一个重载:
1 2 3 4 5 6 7 8 9 10 11 12 13 void AssemblerAarch64::B (Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; B (offsetImm); } void AssemblerAarch64::B (int32_t imm) uint32_t code = BranchOpCode::Branch | ((imm << BRANCH_Imm26_LOWBITS) & BRANCH_Imm26_MASK); EmitU32 (code); }
B.cond B.cond根据条件跳转到一个与程序计数器(PC)相对偏移的标签,并提示这不是一个子程序调用或返回 。
对于<cond>而言,可以使用标准的conditions,可以参考上面所实现的Condition或对应的参考手册。
而<label>相对于该指令地址的偏移量在$±1MB$范围内。
1 2 3 4 5 6 7 8 9 10 11 12 13 void AssemblerAarch64::B (Condition cond, Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; B (cond, offsetImm); } void AssemblerAarch64::B (Condition cond, int32_t imm) uint32_t code = BranchOpCode::BranchCond | BranchImm19 (imm) | cond; EmitU32 (code); }
Br Br无条件地跳转到寄存器中的地址,并提示这不是一个子程序返回 。
1 2 3 4 5 void AssemblerAarch64::Br (const Register &rn) uint32_t code = BranchOpCode::BR | Rn (rn.GetId ()); EmitU32 (code); }
Blr Blr调用寄存器中的地址处的子程序,并将寄存器X30设置为 $PC+4$。
1 2 3 4 5 6 void AssemblerAarch64::Blr (const Register &rn) ASSERT (!rn.IsW ()); uint32_t code = CallOpCode::BLR | Rn (rn.GetId ()); EmitU32 (code); }
Bl Bl跳转到一个与程序计数器(PC)相对偏移的位置,并将寄存器X30设置为$PC+4$。它提示这是一个子程序调用 。
1 2 3 4 5 6 7 8 9 10 11 12 13 void AssemblerAarch64::Bl (Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; Bl (offsetImm); } void AssemblerAarch64::Bl (int32_t imm) uint32_t code = CallOpCode::BL | ((imm << BRANCH_Imm26_LOWBITS) & BRANCH_Imm26_MASK); EmitU32 (code); }
TB TBNZ TBNZ将通用寄存器中的一个位与零进行比较,并在比较结果不等于零时,按PC相对偏移有条件地分支到一个标签。该指令提供一个提示,表示这不是子程序调用或返回。该指令不会影响条件标志 。
1 TBNZ <R><t>, #<imm>, <label>
在这里的<imm>指的是第几位数据,其被$b5:b40$所共同组成。
而<label>和imm14相关,其范围为$+/-32KB$
在实际的处理中,我们依旧提供了imm和Label的两个实现版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void AssemblerAarch64::Tbnz (const Register &rt, int32_t bitPos, Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; Tbnz (rt, bitPos, offsetImm); } void AssemblerAarch64::Tbnz (const Register &rt, int32_t bitPos, int32_t imm) uint32_t b5 = (bitPos << (BRANCH_B5_LOWBITS - 5 )) & BRANCH_B5_MASK; uint32_t b40 = (bitPos << BRANCH_B40_LOWBITS) & BRANCH_B40_MASK; uint32_t imm14 = (imm <<BRANCH_Imm14_LOWBITS) & BRANCH_Imm14_MASK; uint32_t code = b5 | BranchOpCode::TBNZ | b40 | imm14 | rt.GetId (); EmitU32 (code); }
TBZ TBZ将测试位的值与零进行比较,并在比较结果等于零时,按PC相对偏移有条件地分支到一个标签。该指令提供一个提示,表示这不是子程序调用或返回。该指令不会影响条件标志 。
1 TBZ <R><t>, #<imm>, <label>
与TBNZ的实际处理情况相同:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void AssemblerAarch64::Tbz (const Register &rt, int32_t bitPos, Label *label) int32_t offsetImm = LinkAndGetInstOffsetToLabel (label); offsetImm >>= 2 ; Tbz (rt, bitPos, offsetImm); } void AssemblerAarch64::Tbz (const Register &rt, int32_t bitPos, int32_t imm) uint32_t b5 = (bitPos << (BRANCH_B5_LOWBITS - 5 )) & BRANCH_B5_MASK; uint32_t b40 = (bitPos << BRANCH_B40_LOWBITS) & BRANCH_B40_MASK; uint32_t imm14 = (imm << BRANCH_Imm14_LOWBITS) & BRANCH_Imm14_MASK; uint32_t code = b5 | BranchOpCode::TBZ | b40 | imm14 | rt.GetId (); EmitU32 (code); }
TST TST(immediate)指令的作用是对两个操作数执行按位与(AND)运算,但不保存结果。相反,它会根据运算结果设置或清除条件标志寄存器中的相关标志位 。
值得注意的是,TST(immediate)的一个假名则是ADDS(immediate)。
1 2 3 4 5 6 7 ; sf = 0 && N = 0 TST <Wn>, #<imm> equals ANDS WZR, <Wn>, #<imm> ; sf = 1 TST <Xn>, #<imm> equals ANDS XZR, <Xn>, #<imm>
这里的<imm>需要注意:如果在$32-bits$下,其由$imms:immr$组成;在$64-bits$下由$N:imms:immr$组成。
1 2 3 4 void AssemblerAarch64::Tst (const Register &rn, const LogicalImmediate &imm) Ands (Register (Zero, rn.GetType ()), rn, imm); }
TST(shifted register) TST(shifted register)对寄存器值和可选移位的寄存器值执行按位与操作。它根据结果更新条件标志,并丢弃结果 。
值得注意的是,TST(shifted register)的一个假名则是ADDS(shifted register)。
1 2 3 4 5 TST <Wn>, <Wm>{, <shift> #<amount>} ; 32-bits equals ANDS WZR, <Wn>, <Wm>{, <shift> #<amount>} TST <Xn>, <Xm>{, <shift> #<amount>} ; 64-bits equals ANDS XZR, <Xn>, <Xm>{, <shift> #<amount>}
这里的<shift>的可选项为:
Logic 对于ArkTS中的aarch64架构的逻辑部分的汇编实现而言,主要分为Orr和And两类。更重要的是,Orr和And的内部实现实际上是十分相似的,因此我们会使用BitWiseOP这样的函数来统一实现其内部逻辑。
对于Orr和And的具体差异主要在opcode上。
1 2 3 4 5 6 7 8 enum BitwiseOpCode { AND_Imm = 0x12000000 , AND_Shift = 0x0a000000 , ANDS_Imm = 0x72000000 , ANDS_Shift = 0x6a000000 , ORR_Imm = 0x32000000 , ORR_Shift = 0x2a000000 , };
对于immediate下的指令,我们只需要直接传入对应的opcode即可,不需要做多余的处理:
1 2 3 4 5 void AssemblerAarch64::BitWiseOpImm (BitwiseOpCode op, const Register &rd, const Register &rn, uint64_t imm) uint32_t code = Sf (!rd.IsW ()) | op | imm | Rn (rn.GetId ()) | Rd (rd.GetId ()); EmitU32 (code); }
而对于shifted的指令,我们就需要通过之前实现的Operand对shift操作进行具体的处理:
1 2 3 4 5 6 7 8 9 void AssemblerAarch64::BitWiseOpShift (BitwiseOpCode op, const Register &rd, const Register &rn, const Operand &operand) uint32_t shift_field = (operand.GetShiftOption () << BITWISE_OP_Shift_LOWBITS) & BITWISE_OP_Shift_MASK; uint32_t shift_amount = (operand.GetShiftAmount () << BITWISE_OP_ShiftAmount_LOWBITS) & BITWISE_OP_ShiftAmount_MASK; uint32_t code = Sf (!rd.IsW ()) | op | shift_field | Rm (operand.Reg ().GetId ()) | shift_amount | Rn (rn.GetId ()) | Rd (rd.GetId ()); EmitU32 (code); }
这里的类似于BITWISE_OP_Shift_LOWBITS是通过BITWISE_OP_FIELD_LIST宏实现的:
1 2 3 4 5 6 #define BITWISE_OP_FIELD_LIST(V) \ V(BITWISE_OP, N, 22, 22) \ V(BITWISE_OP, Immr, 21, 16) \ V(BITWISE_OP, Shift, 23, 22) \ V(BITWISE_OP, Imms, 15, 10) \ V(BITWISE_OP, ShiftAmount, 15, 10)
Orr immediate对一个寄存器值和一个立即数寄存器值进行按位或(包含或)操作,并将结果写入目标寄存器。该指令可用作别名指令 MOV(bitmask immediate)。
当$Rn = 11111$且!MoveWidePreferred(sf, N, imms, immr)时,可以用作Mov(bitmask immediate)的假名。
1 2 ORR <Wd|WSP>, <Wn>, #<imm> ; 32-bits ORR <Xd|SP>, <Xn>, #<imm> ; 64-bits
对于<imm>而言,再$32bits$下由imms:immr组成;而$64bits$由N:imms:immr组成。
ORR(shifted register) Orr(shifted register)对一个寄存器值和一个可选择进行位移的寄存器值进行按位或(包含或)操作,并将结果写入目标寄存器。该指令可用作别名指令 MOV(register)。
当$shite = 00$且$imm6 = 000000$且$Rn = 11111$时,可以用作Mov(register)的假名。
1 2 ORR <Wd>, <Wn>, <Wm>{, <shift> #<amount>} ; 32-bits ORR <Xd>, <Xn>, <Xm>{, <shift> #<amount>} ; 64-bits
And(immediate)对一个寄存器值和一个立即数值进行按位与操作,并将结果写入目标寄存器 。
1 2 AND <Wd|WSP>, <Wn>, #<imm> ; 32-bits AND <Xd|SP>, <Xn>, #<imm> ; 64-bits
对于<imm>来说,在$32bits$下由imms:immr构成;而$64bits$下由N:imms:immr构成。
AND(shifted register) And(shifted register)对一个寄存器值和一个可选择进行位移的寄存器值进行按位与操作,并将结果写入目标寄存器 。
1 2 AND <Wd>, <Wn>, <Wm>{, <shift> #<amount>} ; 32-bits AND <Xd>, <Xn>, <Xm>{, <shift> #<amount>} ; 64-bits
Ands immediate对一个寄存器值和一个立即数值进行按位与操作,并将结果写入目标寄存器。它根据结果更新条件标志位。该指令可用作别名指令 TST(immediate)。
当$Rd = 11111$时,可以作为TST(immediate)的别名使用。
1 2 ANDS <Wd>, <Wn>, #<imm> ; 32-bits ANDS <Xd>, <Xn>, #<imm> ; 64-bits
对于<imm>而言,再$32bits$下由imms:immr组成;而$64bits$由N:imms:immr组成。
ANDS(shifted register) Ands shifted register对一个寄存器值和一个可选择进行位移的寄存器值进行按位与操作,并将结果写入目标寄存器。它根据结果更新条件标志位。该指令可用作别名指令 TST(shifted register)。
当$Rd = 11111$时,可以作为TST(shifted register)的别名使用。
1 2 ANDS <Wd>, <Wn>, <Wm>{, <shift> #<amount>} ; 32-bits ANDS <Xd>, <Xn>, <Xm>{, <shift> #<amount>} ; 64-bits
Shift LSR(immediate)将一个寄存器值向右移动固定的位数,移入零位,并将结果写入目标寄存器 。
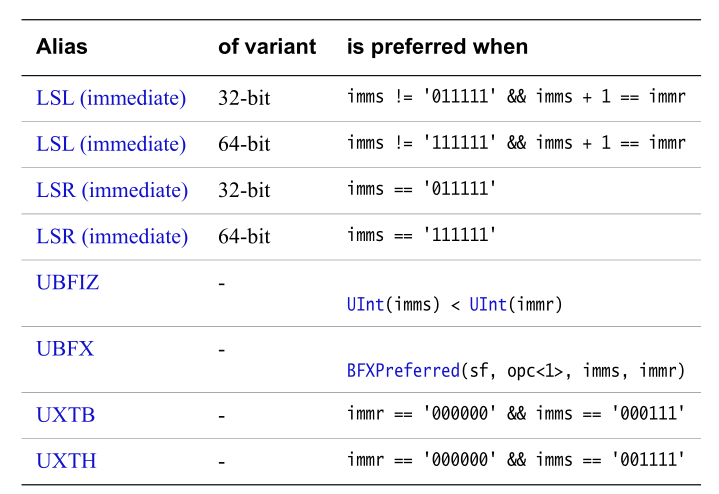
该指令是UBFM指令的别名。这意味着:
在本描述中,编码的命名与UBFM的编码相匹配。
UBFM的描述提供了操作伪代码、任何CONSTRAINED UNPREDICTABLE行为和该指令的操作信息。
1 2 3 4 5 6 7 LSR <Wd>, <Wn>, #<shift> ; 32-bits equals UBFM <Wd>, <Wn>, #<shift>, #31 when sf == 0 && N == 0 && imms == 011111 LSR <Xd>, <Xn>, #<shift> ; 64-bits equals UBFM <Xd>, <Xn>, #<shift>, #63 when sf == 1 && N == 1 && imms == 111111
LSR(register) LSR(register)根据一个可变的位数将一个寄存器值右移,移入零位,并将结果写入目标寄存器。第二个源寄存器除以数据大小所得的余数确定了将第一个源寄存器右移的位数 。
该指令是LSRV指令的别名。这意味着:
在本描述中,编码的命名与LSRV的编码相匹配。
LSRV的描述提供了操作伪代码、任何CONSTRAINED UNPREDICTABLE行为和该指令的操作信息。
1 2 3 4 5 6 7 LSR <Wd>, <Wn>, <Wm> ; 32-bits equals LSRV <Wd>, <Wn>, <Wm> when sf == 0 LSR <Xd>, <Xn>, <Xm> ; 64-bits equals LSRV <Xd>, <Xn>, <Xm> when sf == 1
LSL(register) LSL(register)根据一个可变的位数将一个寄存器值左移,移入零位,并将结果写入目标寄存器。第二个源寄存器除以数据大小所得的余数确定了将第一个源寄存器左移的位数 。
该指令是LSLV指令的别名。这意味着:
在本描述中,编码的命名与LSLV的编码相匹配。
LSLV的描述提供了操作伪代码、任何CONSTRAINED UNPREDICTABLE行为和该指令的操作信息
1 2 3 4 5 6 7 LSL <Wd>, <Wn>, <Wm> ; 32-bits equals LSRV <Wd>, <Wn>, <Wm> when sf == 0 LSL <Xd>, <Xn>, <Xm> ; 64-bits equals LSRV <Xd>, <Xn>, <Xm> when sf == 1
UBFM Unsigned Bitfield Move通常通过其别名访问,这些别名在反汇编时始终优先选择 。
如果$imms \ge immr$,则将源寄存器中从位immr开始的长度为($imms - immr + 1$)位的位域复制到目标寄存器的最低有效位。
如果$imms \lt immr$,则将源寄存器的最低有效位中长度为($imms + 1$)位的位域复制到目标寄存器的位位置($regsize - immr$)处,其中regsize是目标寄存器的大小,可以是$32$位或$64$位。
在这两种情况下,位域下方和上方的目标位都设置为零。
UBFM的使用场景通常为:
位字段操作:从一个寄存器中提取特定的位字段,并将其复制到另一个寄存器中,以进行后续的处理或使用。
数据解析:当处理二进制数据时,可以使用 UBFM 指令来提取特定的位字段,并将其转换为有意义的数值或状态。
该指令可用作别名指令LSL(immediate)、LSR(immediate)、UBFIZ、UBFX、UXTB和UXTH。
1 2 UBFM <Wd>, <Wn>, #<immr>, #<imms> ; 32-bits UBFM <Xd>, <Xn>, #<immr>, #<imms> ; 64-bits
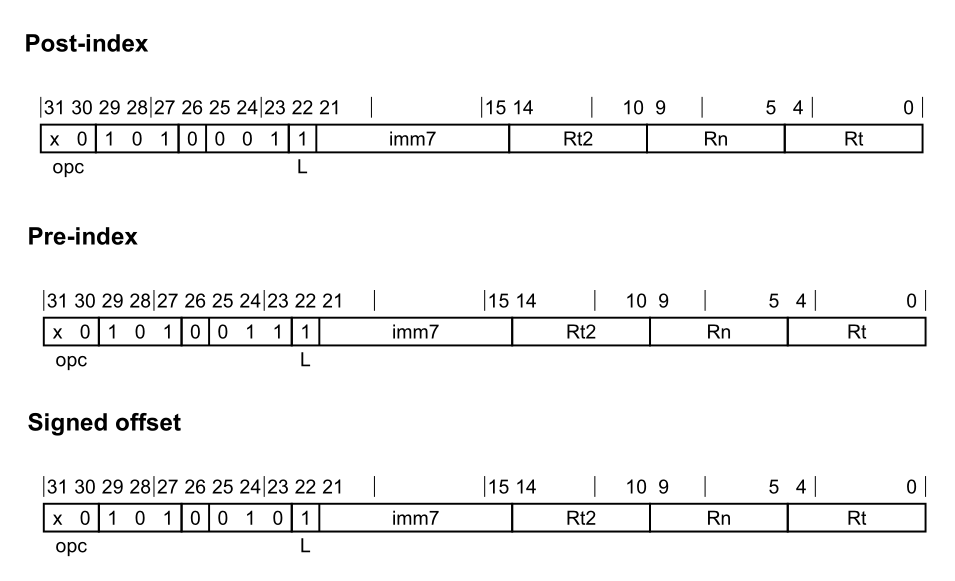
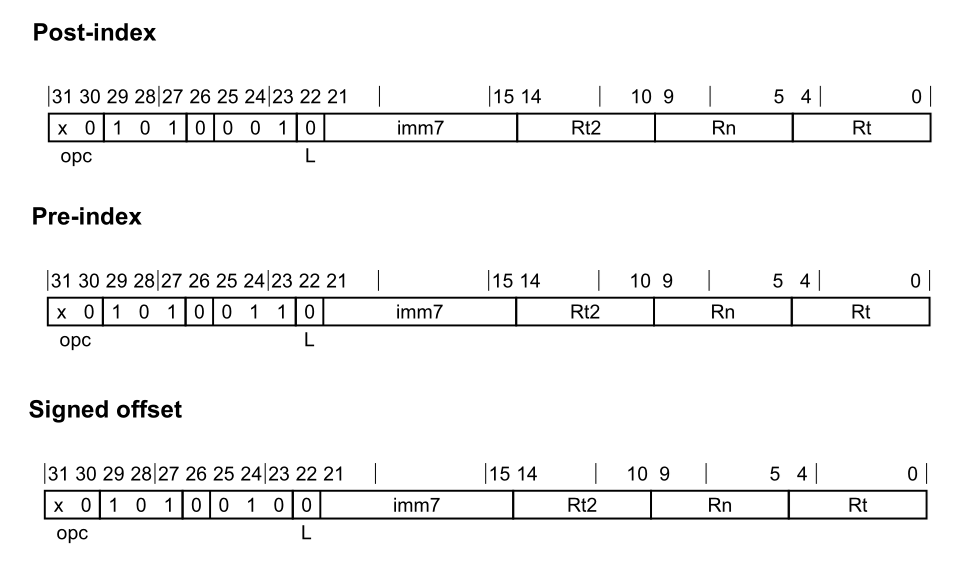
Store and Load LDP LDP指令通过基础寄存器值和立即偏移量计算地址,从内存中加载两个32位字或两个64位双字,并将它们写入两个寄存器中 。
在AddrMode中我们提到,内存模型通常有三种:Post、Pre和Signed offset
1 2 3 4 5 6 7 8 9 10 11 ; Post-index LDP <Wt1>, <Wt2>, [<Xn|SP>], #<imm> ; 32-bits, when opc == 00 LDP <Xt1>, <Xt2>, [<Xn|SP>], #<imm> ; 64-bits, when opc == 10 ; Pre-index LDP <Wt1>, <Wt2>, [<Xn|SP>, #<imm>]! ; 32-bits, when opc == 00 LDP <Xt1>, <Xt2>, [<Xn|SP>, #<imm>]! ; 64-bits, when opc == 10 ; Signed offset LDP <Wt1>, <Wt2>, [<Xn|SP>{, #<imm>}] ; 32-bits, when opc == 00 LDP <Xt1>, <Xt2>, [<Xn|SP>{, #<imm>}] ; 64-bits, when opc == 10
对于<imm>有以下的解释:
对于32位Post-index和32位Pre-index变体:有符号的立即字节偏移量在范围$-256 ~ 252$之间,是4的倍数,并在imm7字段中编码为$imm/4$。
对于32位Signed offset变体:可选的有符号立即字节偏移量在范围$-256 ~ 252$之间,是4的倍数,默认为0,并在imm7字段中编码为$imm/4$。
对于64位Post-index和64位Pre-index变体:有符号的立即字节偏移量在范围$-512 ~ 504$之间,是8的倍数,并在imm7字段中编码为$imm/8$。
对于64位Signed offset变体:可选的有符号立即字节偏移量在范围$-512 ~ 504$之间,是8的倍数,默认为0,并在imm7字段中编码为$imm/8$。
而在实际的代码处理中,也能够很好的体现上面所说的:
1 2 3 4 5 6 7 8 9 10 11 enum LoadStorePairOpCode { LDP_Post = 0x28c00000 , LDP_Pre = 0x29c00000 , LDP_Offset = 0x29400000 , }; if (sf) { imm >>= 3 ; } else { imm >>= 2 ; }
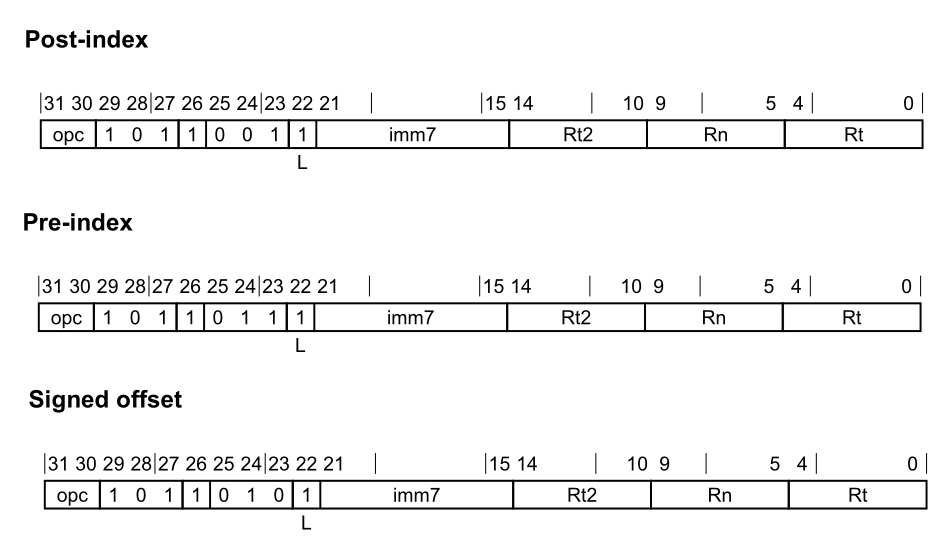
Vector LDP LDP(SIMD&FP)指令从内存中加载一对SIMD&FP寄存器。用于加载的地址是根据基础寄存器值和可选的立即偏移量计算得出的 。
根据CPACR_EL1、CPTR_EL2和CPTR_EL3寄存器中的设置以及当前的安全状态和异常级别,执行该指令的尝试可能会被捕获。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ; Post-index LDP <St1>, <St2>, [<Xn|SP>], #<imm> ; 32-bits, when opc == 00(S) LDP <Dt1>, <Dt2>, [<Xn|SP>], #<imm> ; 64-bits, when opc == 01(D) LDP <Qt1>, <Qt2>, [<Xn|SP>], #<imm> ; 128-bits, when opc == 10(Q) ; Pre-index LDP <St1>, <St2>, [<Xn|SP>, #<imm>]! ; 32-bits, when opc == 00(S) LDP <Dt1>, <Dt2>, [<Xn|SP>, #<imm>]! ; 64-bits, when opc == 01(D) LDP <Qt1>, <Qt2>, [<Xn|SP>, #<imm>]! ; 128-bits, when opc == 10(Q) ; Signed offset LDP <St1>, <St2>, [<Xn|SP>{, #<imm>}] ; 32-bits, when opc == 00(S) LDP <Dt1>, <Dt2>, [<Xn|SP>{, #<imm>}] ; 64-bits, when opc == 01(D) LDP <Qt1>, <Qt2>, [<Xn|SP>{, #<imm>}] ; 128-bits, when opc == 10(Q)
对于<imm>有以下解释:
对于32位Post-index和32位Pre-index变体:有符号的立即字节偏移量在范围$-256 ~ 252$之间,是4的倍数,并在imm7字段中编码为$imm / 4$。
对于32位Signed offset变体:可选的有符号立即字节偏移量在范围$-256 ~ 252$之间,是4的倍数,默认为0,并在imm7字段中编码为$imm / 4$。
对于64位Post-index和64位Pre-index变体:有符号的立即字节偏移量在范围$-512 ~ 504$之间,是8的倍数,并在imm7字段中编码为$imm / 8$。
对于64位Signed offset变体:可选的有符号立即字节偏移量在范围$-512 ~ 504$之间,是8的倍数,默认为0,并在imm7字段中编码为$imm / 8$。
对于128位Post-index和128位Pre-index变体:有符号的立即字节偏移量在范围$-1024 ~ 1008$之间,是16的倍数,并在imm7字段中编码为$imm / 16$。
对于128位Signed offset变体:可选的有符号立即字节偏移量在范围$-1024 ~ 1008$之间,是16的倍数,默认为0,并在imm7字段中编码为$imm / 16$。
其具体视线中,也能够体现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 switch (vt.GetScale ()) { case S: imm >>= 2 ; break ; case D: imm >>= 3 ; break ; case Q: imm >>= 4 ; break ; default : LOG_ECMA (FATAL) << "this branch is unreachable" ; UNREACHABLE (); }
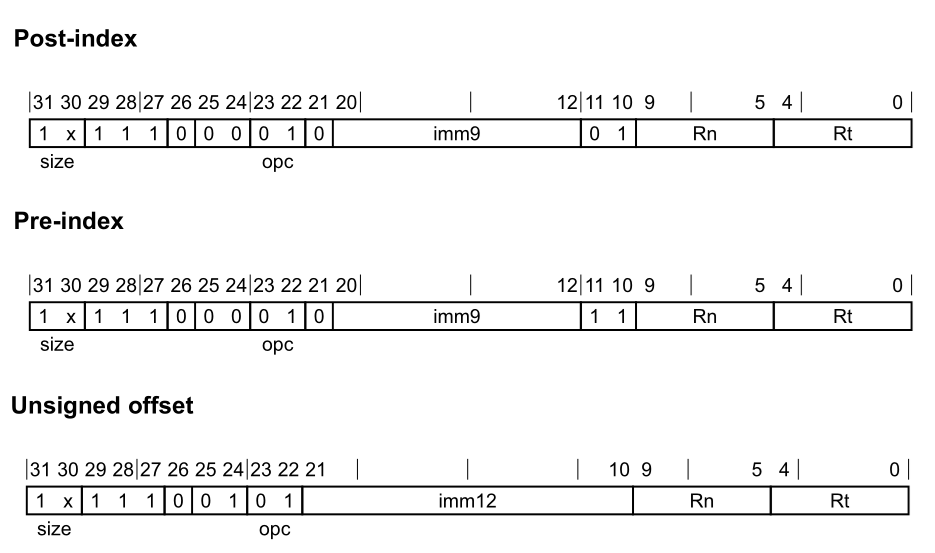
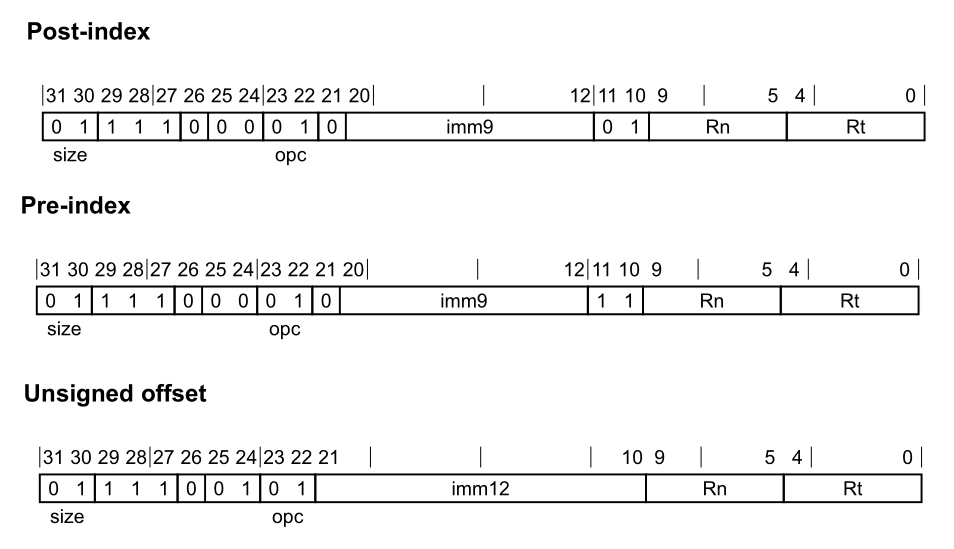
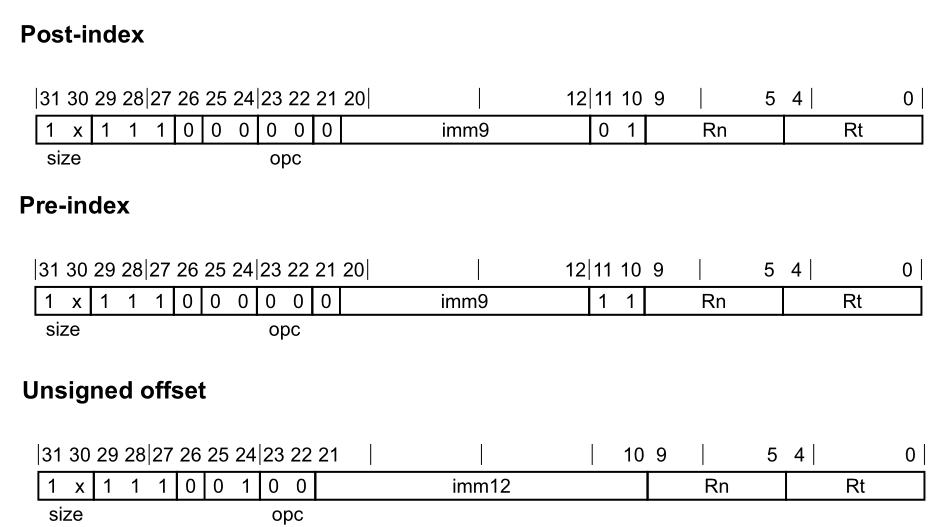
LDR(immediate)指令从内存中加载一个字或双字,并将其写入一个寄存器。用于加载的地址是根据基础寄存器和立即偏移量计算得出的。无符号偏移量变体会将立即偏移量的值按照所访问值的大小进行缩放,然后再将其加到基础寄存器值上 。
1 2 3 4 5 6 7 8 9 10 11 ; Post-index LDR <Wt>, [<Xn|SP>], #<simm> ; 32-bits, when size == 10 LDR <Xt>, [<Xn|SP>], #<simm> ; 64-bits, when size == 11 ; Pre-index LDR <Wt>, [<Xn|SP>, #<simm>]! ; 32-bits, when size == 10 LDR <Xt>, [<Xn|SP>, #<simm>]! ; 64-bits, when size == 11 ; Signed offset LDR <Wt>, [<Xn|SP>{, #<pimm>}] ; 32-bits, when size == 10 LDR <Xt>, [<Xn|SP>{, #<pimm>}] ; 64-bits, when size == 11
实际中,我们在Ldr函数中共同处理了两种情况,这里给出ldr(immediate)的处理逻辑:
1 2 3 4 5 6 7 8 if (operand.IsImmediateOffset ()) { uint64_t imm = GetImmOfLdr (operand, scale, regX); bool isSigned = operand.GetAddrMode () != AddrMode::OFFSET; uint32_t instructionCode = ((regX && (scale == Scale::Q)) << 30 ) | op | LoadAndStoreImm (imm, isSigned) | Rn (operand.GetRegBase ().GetId ()) | Rt (rt.GetId ()); EmitU32 (instructionCode); }
LDR(register) LDR(register)指令根据基础寄存器值和偏移寄存器值计算一个地址,从内存中加载一个字,并将其写入一个寄存器。偏移寄存器值可以选择进行位移和扩展操作 。
1 2 LDR <Wt>, [<Xn|SP>, (<Wm>|<Xm>){, <extend> {<amount>}}] ; 32-bits, when size == 10 LDR <Xt>, [<Xn|SP>, (<Wm>|<Xm>){, <extend> {<amount>}}] ; 64-bits, when size == 11
<extend>是索引扩展/位移说明符(index extend/shift specifier),默认为LSL(左移)。当<amount>被省略时,必须为LSL省略<extend>。其解码为option字段。它可以具有以下值:
1 2 3 4 UXTW when option = 010 LSL when option = 011 SXTW when option = 110 SXTX when option = 111
<amount>是唯一索引量,当<extend>不为LSL时可选。当允许被选中时,其默认值为0,被解码为S字段:
1 2 3 4 5 6 7 ; 32-bits #0 when S = 0 #2 when S = 1 ; 64-bits #0 when S = 0 #3 when S = 1
LDRB(immediate)从内存中加载一个字节,对其进行零扩展,并将结果写入寄存器。用于加载的地址是从基寄存器和立即偏移量计算出来的 。
1 2 3 4 5 6 7 8 ; Post-index LDRB <Wt>, [<Xn|SP>], #<simm> ; Pre-index LDRB <Wt>, [<Xn|SP>, #<simm>]! ; Signed offset LDRB <Wt>, [<Xn|SP>{, #<pimm>}]
对于LDRB的具体实现,直接通过LDR进行实现:
1 2 3 4 5 void AssemblerAarch64::Ldrb (const Register &rt, const MemoryOperand &operand) ASSERT (rt.IsW ()); Ldr (rt, operand, Scale::B); }
LDRB(register) LDRB(register)从基寄存器值和偏移寄存器值计算一个地址,从内存中加载一个字节,对其进行零扩展,并将其写入寄存器 。
1 2 3 4 5 ; Extended register LDRB <Wt>, [<Xn|SP>, (<Wm>|<Xm>), <extend> {<amount>}] ; when option != 011 . ; Shifted register LDRB <Wt>, [<Xn|SP>, <Xm>{, LSL <amount>}] ; when option == 011
LDRH(immediate)从内存中加载半字,对其进行零扩展,并将结果写入寄存器。用于加载的地址是从基寄存器和立即偏移量计算出来的 。
1 2 3 4 5 6 7 8 ; Post-index LDRH <Wt>, [<Xn|SP>], #<simm> ; Pre-index LDRH <Wt>, [<Xn|SP>, #<simm>]! ; Unsigned offset LDRH <Wt>, [<Xn|SP>{, #<pimm>}]
其内部实现由LDR构成:
1 2 3 4 5 void AssemblerAarch64::Ldrh (const Register &rt, const MemoryOperand &operand) ASSERT (rt.IsW ()); Ldr (rt, operand, Scale::H); }
LDRH(register) LDRH(register)从基寄存器值和偏移寄存器值计算地址,从内存中加载半字,对其进行零扩展,并将其写入寄存器 。
1 LDRH <Wt>, [<Xn|SP>, (<Wm>|<Xm>){, <extend> {<amount>}}]
LDUR LDUR从基寄存器和直接偏移量中计算一个地址,从内存中加载一个32位字或64位双字,对其进行零扩展,并将其写入寄存器 。
1 2 LDUR <Wt>, [<Xn|SP>{, #<simm>}] ; 32-bits, when size == 10 LDUR <Xt>, [<Xn|SP>{, #<simm>}] ; 64-bits, when size == 11
其具体实现为:
1 2 3 4 5 6 7 8 9 10 11 void AssemblerAarch64::Ldur (const Register &rt, const MemoryOperand &operand) bool regX = !rt.IsW (); uint32_t op = LDUR_Offset; ASSERT (operand.IsImmediateOffset ()); uint64_t imm = static_cast <uint64_t >(operand.GetImmediate ().Value ()); uint32_t instructionCode = (regX << 30 ) | op | LoadAndStoreImm (imm, true ) | Rn (operand.GetRegBase ().GetId ()) | Rt (rt.GetId ()); EmitU32 (instructionCode); }
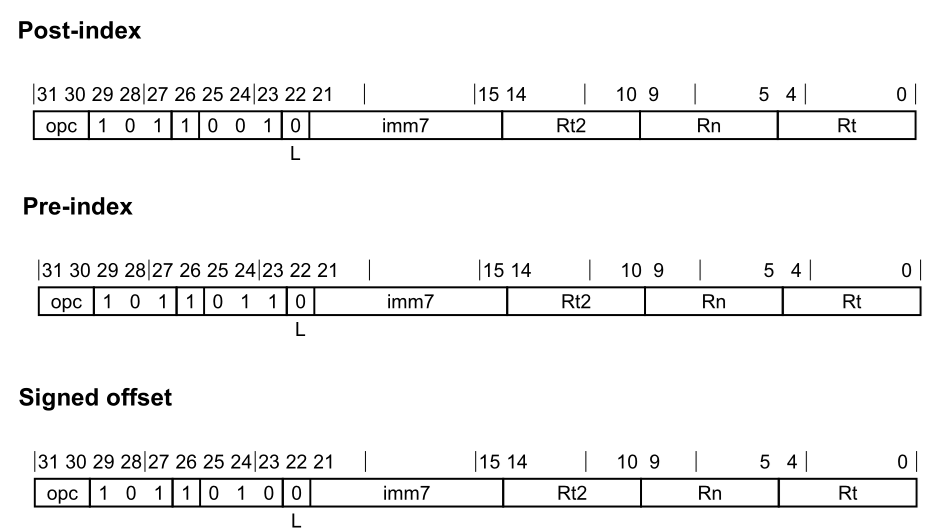
STP STP从基寄存器值和直接偏移量计算地址,并从两个寄存器中存储两个32位字或两个64位双字到计算的地址 。
1 2 3 4 5 6 7 8 9 10 11 ; Post-index STP <Wt1>, <Wt2>, [<Xn|SP>], #<imm> ; 32-bits, when opc == 00 STP <Xt1>, <Xt2>, [<Xn|SP>], #<imm> ; 64-bits, when opc == 01 ; Pre-index STP <Wt1>, <Wt2>, [<Xn|SP>, #<imm>]! ; 32-bits, when opc == 00 STP <Xt1>, <Xt2>, [<Xn|SP>, #<imm>]! ; 64-bits, when opc == 01 ; Signed offset STP <Wt1>, <Wt2>, [<Xn|SP>{, #<imm>}] ; 32-bits, when opc == 00 STP <Xt1>, <Xt2>, [<Xn|SP>{, #<imm>}] ; 64-bits, when opc == 01
对于STP的实际实现,主要代码片段为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 case OFFSET: op = LoadStorePairOpCode::STP_Offset; break ; case PREINDEX: op = LoadStorePairOpCode::STP_Pre; break ; case POSTINDEX: op = LoadStorePairOpCode::STP_Post; break ; if (sf) { imm >>= 3 ; } else { imm >>= 2 ; }
Vector STP STP(SIMD&FP)将一对SIMD&FP寄存器存储到内存中。用于存储的地址是从基寄存器值和立即偏移量计算出来的 。
根据CPACR_EL1、CPTR_EL2和CPTR_EL3寄存器中的设置,以及当前的安全状态和Exception级别,执行指令的尝试可能会被捕获。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ; Post-index STP <St1>, <St2>, [<Xn|SP>], #<imm> ; 32-bits, when opc == 00(S) STP <Dt1>, <Dt2>, [<Xn|SP>], #<imm> ; 64-bits, when opc == 01(D) STP <Qt1>, <Qt2>, [<Xn|SP>], #<imm> ; 128-bits, when opc == 10(Q) ; Pre-index STP <St1>, <St2>, [<Xn|SP>, #<imm>]! ; 32-bits, when opc == 00(S) STP <Dt1>, <Dt2>, [<Xn|SP>, #<imm>]! ; 64-bits, when opc == 01(D) STP <Qt1>, <Qt2>, [<Xn|SP>, #<imm>]! ; 128-bits, when opc == 10(Q) ; Signed offset STP <St1>, <St2>, [<Xn|SP>{, #<imm>}] ; 32-bits, when opc == 00(S) STP <Dt1>, <Dt2>, [<Xn|SP>{, #<imm>}] ; 64-bits, when opc == 01(D) STP <Qt1>, <Qt2>, [<Xn|SP>{, #<imm>}] ; 128-bits, when opc == 10(Q)
其代码的主要部分为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 case OFFSET: op = LoadStorePairOpCode::STP_V_Offset; break ; case PREINDEX: op = LoadStorePairOpCode::STP_V_Pre; break ; case POSTINDEX: op = LoadStorePairOpCode::STP_V_Post; break ; case S: imm >>= 2 ; break ; case D: imm >>= 3 ; break ; case Q: imm >>= 4 ; break ;
STR STR将一个字或双字从寄存器存储到存储器中。用于存储的地址是从基寄存器和立即偏移量计算出来的 。
1 2 3 4 5 6 7 8 9 10 11 ; Post-index STR <Wt>, [<Xn|SP>], #<simm> ; 32-bits, when size == 10 STR <Xt>, [<Xn|SP>], #<simm> ; 64-bits, when size == 11 ; Pre-index STR <Wt>, [<Xn|SP>, #<simm>]! ; 32-bits, when size == 10 STR <Xt>, [<Xn|SP>, #<simm>]! ; 64-bits, when size == 11 ; Unsigned offset STR <Wt>, [<Xn|SP>{, #<pimm>}] ; 32-bits, when size == 10 STR <Xt>, [<Xn|SP>{, #<pimm>}] ; 64-bits, when size == 11
在ArkTS中,主要实现了str(immediate)其内部的主要实现为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 case OFFSET: op = LoadStoreOpCode::STR_Offset; if (regX) { imm >>= 3 ; } else { imm >>= 2 ; } isSigned = false ; break ; case PREINDEX: op = LoadStoreOpCode::STR_Pre; break ; case POSTINDEX: op = LoadStoreOpCode::STR_Post; break ;
STUR STUR从基本寄存器值和直接偏移量计算一个地址,并从寄存器中存储一个32位字或64位双字到计算出的地址 。
1 2 STUR <Wt>, [<Xn|SP>{, #<simm>}] ; 32-bits, when size == 10 STUR <Xt>, [<Xn|SP>{, #<simm>}] ; 64-bits, when size == 11
其内部实现为:
1 2 3 4 5 6 7 8 9 10 11 void AssemblerAarch64::Ldur (const Register &rt, const MemoryOperand &operand) bool regX = !rt.IsW (); uint32_t op = LDUR_Offset; ASSERT (operand.IsImmediateOffset ()); uint64_t imm = static_cast <uint64_t >(operand.GetImmediate ().Value ()); uint32_t instructionCode = (regX << 30 ) | op | LoadAndStoreImm (imm, true ) | Rn (operand.GetRegBase ().GetId ()) | Rt (rt.GetId ()); EmitU32 (instructionCode); }
至此,ArkTS的Aarch汇编的分析到此结束了。