ArkTS RISC-V64 Assembler
在这一节中,我们会主要分析ArkTS中的RISC-V架构的汇编,这也是我们的主要目标之一。当前分析的版本位于ArkTS Runtime[commit 2d8e197]。
RISC-V64 Detail
在开始分析实际代码前,我们需要了解一点RISC-V的相关知识。RISC-V是一种RISC架构的汇编语言,因此和CISC相比,其汇编更加精简。在RISC-V中主要把汇编分为了几种对应的类型,如下所示:
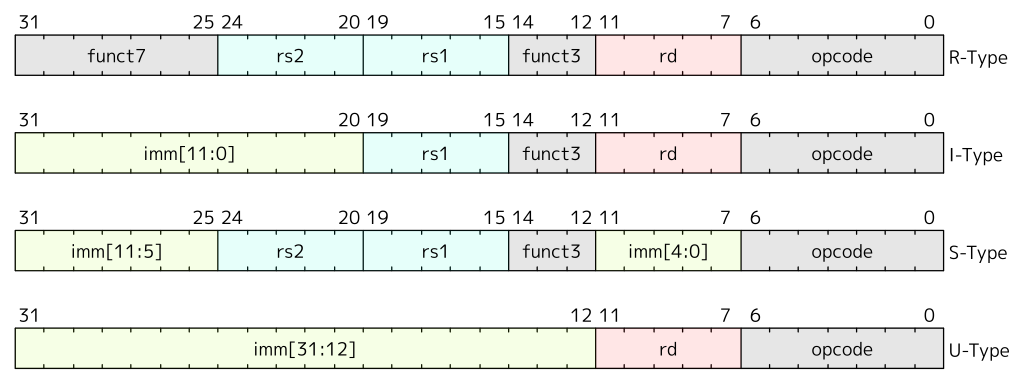
在基础的RV32I指令集中,如上图所示,有四种主要的指令格式(R/I/S/U)。在这里,所有的指令集的长度都被固定为$32-bits$,并且基础指令集是$IALIGN=32$的吗,这就意味着内存中的指令集必须以四字节对齐。如果目标地址没有按$IALIGN$位对齐,则在获取的分支或无条件跳转上生成指令地址不对齐异常。该异常报告在分支或跳转指令上,而不是在目标指令上。对于未采用的条件分支,不会生成指令地址不对齐异常。
RISC-V指令集架构在所有格式中都保持源寄存器(rs1和rs2)和目标寄存器(rd)处于相同位置,以简化解码。除了用于CSR指令的5位立即数外,立即数总是符号扩展的,并且通常打包到指令中最左边的可用位,这样分配是为了减少硬件复杂性。特别是,所有立即数的符号位总是位于指令的第31位,以加快符号扩展电路的速度。
除了上面的四种主要指令格式之外,基础指令集还提供了关于B和J指令格式的变种:

S格式和B格式之间的唯一区别在于,B格式中12位立即数字段用于以2的倍数编码分支偏移。通常做法是在硬件中将指令编码的立即数的所有位左移一位,而在这里,中间位(imm[10:1])和符号位保持在固定位置,而S格式中的最低位(inst[7])在B格式中编码为高位。
RV32
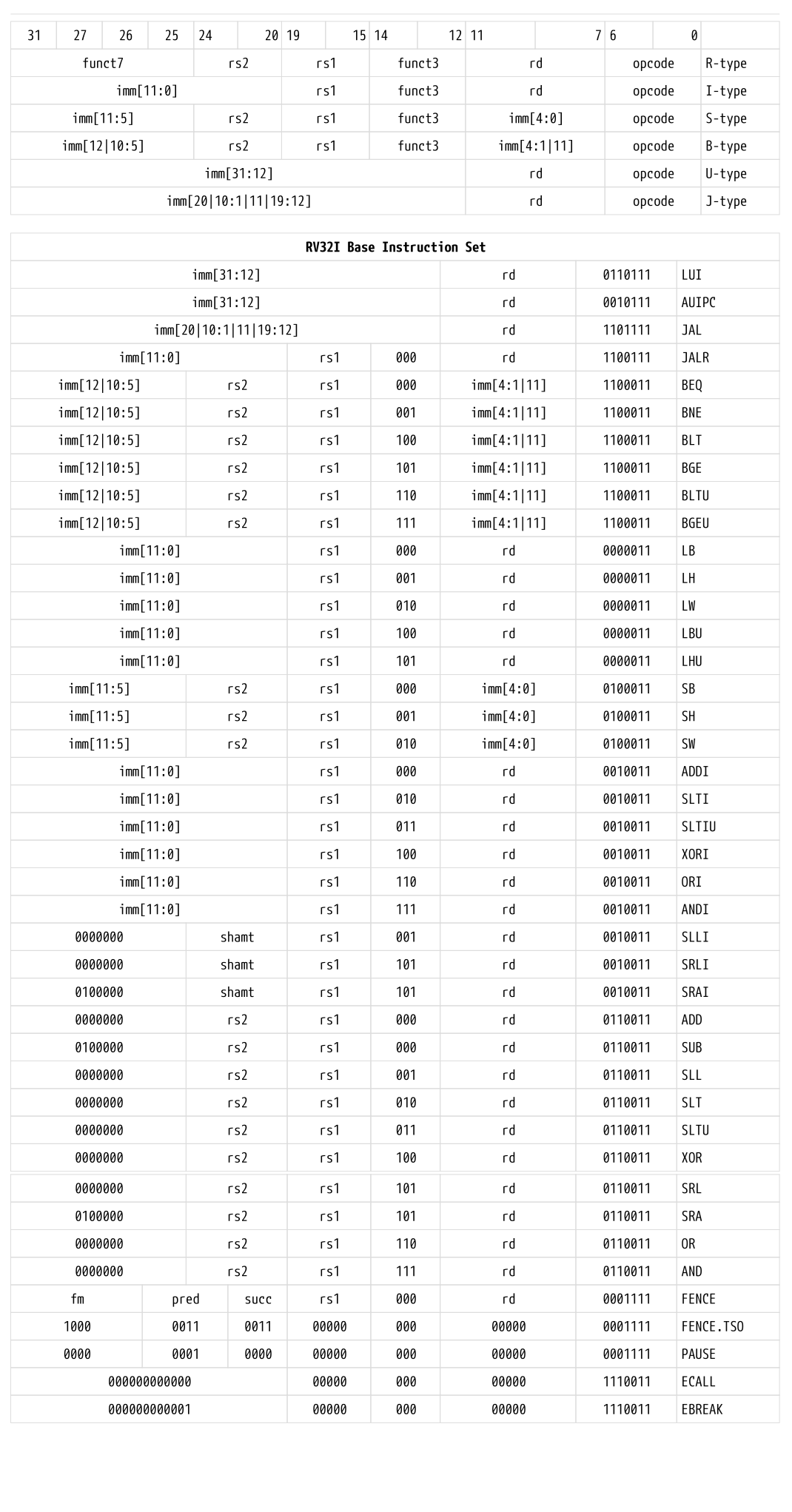
在RISC-V汇编中,单独分析一条汇编是繁琐的,因为RISC-V通常是一组汇编一起分析,通过对应的funct code和opcode就能够确定其具体为哪一条指令。

RV32-Immediate

ADDI指令将符号扩展的12位立即数加到寄存器rs1。算术溢出被忽略,结果仅保留低XLEN位。ADDI rd, rs1, 0用于实现汇编伪指令MV rd, rs1。
SLTI指令将值1写入寄存器rd,如果寄存器rs1小于符号扩展的立即数(两者都作为有符号数处理),否则将0写入rd。SLTIU与SLTI类似,但将值作为无符号数进行比较(即,立即数首先符号扩展到$XLEN$位,然后作为无符号数处理)。注意,SLTIU rd, rs1, 1如果$rs1 = 0$则将rd置为1,否则置为0(汇编伪指令SEQZ rd, rs)。
ANDI, ORI, XORI是逻辑操作指令,对寄存器rs1和符号扩展的12位立即数执行按位与、或和异或操作,并将结果放入rd。注意,XORI rd, rs1, -1对寄存器rs1执行按位逻辑反转(汇编伪指令NOT rd, rs)。

按常数进行移位的指令被编码为I型格式的特化形式。要移位的操作数在rs1中,移位量编码在I型立即数字段的低5位。右移的类型编码在第30位。SLLI是逻辑左移(零被移入低位);SRLI是逻辑右移(零被移入高位);SRAI是算术右移(原符号位被复制到空出的高位)。

LUI用于构建32位常量,使用U型格式。LUI将32位U型立即数值放入目标寄存器rd中,最低的12位填充为零。
AUIPC用于构建相对于程序计数器(pc)的地址,使用U型格式。AUIPC形成一个32位偏移量,最低的12位填充为零,将此偏移量加到AUIPC指令的地址上,然后将结果放入寄存器rd中。
RV32-Register
RV32I定义了几种算术R型操作。所有操作都读取rs1和rs2寄存器作为源操作数,并将结果写入rd寄存器。funct7和funct3字段选择操作的类型。

ADD执行rs1和rs2的加法。SUB执行rs1减去rs2的减法。溢出被忽略,结果的低$XLEN$位写入目标寄存器rd。SLT和SLTU分别执行有符号和无符号比较,如果$rs1 lt rs2$,则将1写入rd,否则写入0。注意,SLTU rd, x0, rs2如果$rs \ne 0$则将rd置为1,否则置为0(汇编伪指令SNEZ rd, rs)。AND、OR和XOR执行按位逻辑运算。
SLL、SRL和SRA分别对寄存器rs1中的值按寄存器rs2低5位中的移位量执行逻辑左移、逻辑右移和算术右移。
RV32-NOP

NOP指令不会改变任何架构上可见的状态,除了推进程序计数器(pc)和增加任何适用的性能计数器。NOP被编码为ADDI x0, x0, 0。
RV32-Jump
RV32I提供了两种类型的控制转移指令:无条件跳转和条件分支。RV32I中的控制转移指令没有架构上可见的延迟槽。如果在跳转或已执行分支的目标上发生指令访问故障或指令页故障异常,则异常在目标指令上报告,而不是在跳转或分支指令上报告。
跳转并链接(JAL)指令使用J型格式,其中J型立即数编码为以2字节为单位的有符号偏移量。偏移量被符号扩展并加到跳转指令的地址上,以形成跳转目标地址。因此,跳转可以目标$±1 MiB$的范围。JAL将跳转后指令$pc+4$的地址存储到寄存器rd中。标准的软件调用约定使用x1作为返回地址寄存器,并使用x5作为备用链接寄存器。
普通无条件跳转(汇编伪指令J)被编码为$rd=x0$的JAL。

间接跳转指令JAL(跳转并链接寄存器)使用I型编码。目标地址通过将符号扩展的12位I型立即数加到寄存器rs1上获得,然后将结果的最低有效位设为零。跳转后指令($pc+4$)的地址写入寄存器rd。如果不需要结果,可以使用寄存器x0作为目标寄存器。

如果目标地址未对齐到四字节边界, JAL和JALR指令将生成指令地址未对齐异常。
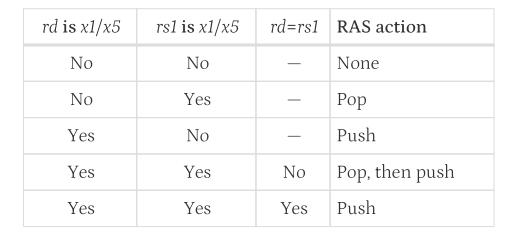
返回地址预测堆栈是高性能指令获取单元的常见特性,但需要准确检测用于过程调用和返回的指令才能有效。对于RISC-V,指令使用的提示通过使用的寄存器编号隐式编码。仅当JAL指令的rd是x1或x5时,才应将返回地址推入返回地址堆栈(RAS)。JALR指令应根据下图所示推入/弹出RAS。
RV32-Branch
所有分支指令都使用B型指令格式。12位B型立即数以2字节为单位编码有符号偏移量。偏移量被符号扩展并加到分支指令的地址上,以得出目标地址。条件分支范围为$±4 KiB$。

分支指令比较两个寄存器。BEQ和BNE分别在寄存器rs1和rs2相等或不等时执行分支。BLT和BLTU分别在使用有符号和无符号比较时$rs1 \lt rs2$时执行分支。BGE和BGEU分别在使用有符号和无符号比较时$rs1 \ge rs2$时执行分支。注意,BGT、BGTU、BLE和BLEU可以通过反转BLT、BLTU、BGE和BGEU的操作数来合成。
RV32-LoadStore
RV32I是一种load-store架构,其中只有加载和存储指令访问内存,算术指令只对CPU寄存器进行操作。RV32I提供一个32位的地址空间,以字节为单位寻址。EEI(执行环境接口)将定义哪些部分的地址空间可以使用哪些指令进行访问(例如,某些地址可能是只读的,或者只支持字访问)。即使目标寄存器是x0的加载操作,仍必须引发任何异常并引起其他副作用,即使加载的值被丢弃。
EEI将定义内存系统是小端序还是大端序。在RISC-V中,端序是字节地址不变的。

加载和存储指令在寄存器和内存之间传输值。加载指令使用I型格式编码,存储指令使用S型格式。有效地址通过将寄存器rs1与符号扩展的12位偏移量相加获得。加载指令将内存中的值复制到寄存器rd。存储指令将寄存器rs2中的值复制到内存中。
LW指令将32位值从内存加载到rd中。LH从内存加载16位值,然后符号扩展到32位后存储在rd中。LHU从内存加载16位值,但随后零扩展到32位后存储在rd中。LB和LBU类似地定义为加载8位值。SW、SH和SB指令将32位、16位和8位值从寄存器rs2的低位存储到内存中。
RV32-Memory

FENCE指令用于对设备I/O和内存访问进行排序,使其在其他RISC-V处理器核(hart)和外部设备或协处理器看来有序。可以将设备输入(I)、设备输出(O)、内存读取(R)和内存写入(W)的任意组合相对于相同的任意组合进行排序。非正式地说, FENCE之后的继承集合中的任何操作,在FENCE之前的前置集合中的任何操作完成之前,不能被其他RISC-V处理器核或外部设备观察到。
FENCE指令还对处理器核进行的内存读写操作相对于外部设备进行的内存读写操作进行排序。然而,FENCE不对外部设备使用任何其他信号机制进行的事件观察进行排序。
EEI将定义哪些I/O操作是可能的,特别是哪些内存地址在被加载和存储指令访问时将分别被视为设备输入和设备输出操作,而不是内存读写操作。例如,通常使用未缓存的加载和存储访问内存映射的I/O设备,这些操作使用I和O位进行排序,而不是使用R和W位。指令集扩展可能还会描述新的I/O指令,这些指令也将使用FENCE中的I和O位进行排序。

fence模式字段fm定义了FENCE指令的语义。$fm=0000$的FENCE指令在其继承集合中的所有内存操作之前排序其前置集合中的所有内存操作。
FENCE.TSO指令被编码为$fm=1000$、前置集合=RW、继承集合=RW的FENCE指令。FENCE.TSO指令在其前置集合中的所有加载操作之前排序其继承集合中的所有内存操作,并在其前置集合中的所有存储操作之前排序其继承集合中的所有存储操作。这使得FENCE.TSO的前置集合中的非AMO存储操作与其继承集合中的非AMO加载操作不排序。
RV32-Env
SYSTEM指令用于访问可能需要特权访问的系统功能,并使用I型指令格式编码。这些指令可以分为两大类:atomically read-modify-write control和状态寄存器(CSR)的指令,以及所有其他潜在的特权指令。CSR指令需要单独描述,基本的非特权指令在以下部分描述。

ECALL指令用于向执行环境发出服务请求。EEI将定义如何传递服务请求的参数,但通常这些参数将在整数寄存器文件中的指定位置。
EBREAK指令用于将控制权返回到调试环境。
RV64
RV64I将整数寄存器和支持的用户地址空间扩展到64位($XLEN=64$)。
RV64-Immediate
大多数整数计算指令操作$XLEN$位值。在RV64I中提供了额外的指令变体,用于操作32位值,这些指令的操作码以 W 后缀表示。这些 *W 指令忽略输入的高32位,并始终生成32位有符号值,将它们符号扩展到64位,即位 $XLEN-1$ 到 31 是相等的。

ADDIW是RV64I指令,将符号扩展的12位立即数加到寄存器rs1,并在rd中生成正确符号扩展的32位结果。溢出被忽略,结果是低32位的符号扩展到64位的结果。注意,ADDIW rd, rs1, 0将寄存器rs1的低32位的符号扩展写入寄存器rd(汇编伪指令 SEXT.W)。

常量移位指令使用与RV32I相同的指令操作码作为I型格式的特化。待移位的操作数在rs1中,移位量在RV64I的I型立即数字段的低6位中编码。右移类型在第30位中编码。SLLI是逻辑左移(零被移入低位);SRLI是逻辑右移(零被移入高位);SRAI是算术右移(原始符号位被复制到腾出的高位)。

SLLIW、SRLIW 和 SRAIW 是仅 RV64I 支持的指令,它们以类似的方式定义,但作用于 32 位值,并将其 32 位结果符号扩展到 64 位。$imm[5] \ne 0$ 的 SLLIW、SRLIW 和 SRAIW 编码是保留的。

LUI使用与 RV32I 相同的操作码。LUI 将 32 位 U 型立即数放入寄存器 rd,并用零填充最低的 12 位。32 位结果被符号扩展到 64 位。
AUIPC使用与 RV32I 相同的操作码。AUIPC 用于构建相对于 pc 的地址,并使用 U 型格式。AUIPC 从 U 型立即数形成一个 32 位偏移量,填充最低的 12 位为零,将结果符号扩展到 64 位,将其加到 AUIPC 指令的地址,然后将结果放入寄存器 rd。
RV64-Register

ADDW 和 SUBW 是仅 RV64I 支持的指令,定义类似于 ADD 和 SUB,但作用于 32 位值并生成有符号的 32 位结果。溢出被忽略,结果的低 32 位被符号扩展到 64 位并写入目标寄存器。
SLL、SRL 和 SRA 对寄存器 rs1 中的值执行逻辑左移、逻辑右移和算术右移,移位量由寄存器 rs2 中的值决定。在 RV64I 中,仅考虑 rs2 的低 6 位作为移位量。
SLLW、SRLW 和 SRAW 是仅 RV64I 支持的指令,定义类似,但作用于 32 位值并将其 32 位结果符号扩展到 64 位。移位量由 rs2[4:0] 给出。
RV64-LoadStore
RV64I 将地址空间扩展到 64 位。执行环境将定义哪些部分的地址空间是合法访问的。

在 RV64I 中,LD 指令从内存中加载一个 64 位值到寄存器 rd。
在 RV64I 中,LW 指令从内存中加载一个 32 位值,并将其符号扩展到 64 位后存储到寄存器 rd。而 LWU 指令则将内存中的 32 位值零扩展到 64 位。同样,LH 和 LHU 对 16 位值的操作与此类似,LB 和 LBU 对 8 位值的操作也类似。SD、SW、SH 和 SB 指令分别将寄存器 rs2 的低位的 64 位、32 位、16 位和 8 位值存储到内存中。
RV Instructions

RISC-V64 Code Detail
对于ArkTS的RISC-V64来说,我们的第一步还是先要确定其对应的寄存器(因为过长,此处就不贴出代码)。我们使用enum RegisterId : uint8_t来对每一个寄存器进行定义。
为了简化操作,我们同时也需要对Opcode和funct进行定义,这样就能够明确的确定一条指令:
1 | enum opCode { |
在ArkTS中,我们依旧需要考虑$32bits$和$64bits$这两种情况,因此需要定义一个结构用于声明:
1 | enum RegisterType { |
同时,和Aarch64一致,我们在处理汇编时需要对汇编的字段进行操作,因此我们需要分割每一条指令的字段,因此就采用了通常的方式使用宏进行分割:
1 |
|
RISC-V64 Header
在assembler_riscv64.h中,我们首先需要注意的就是$XLEN$和各种字段类型处理。对于字段类型的处理而言,我们可以参考aarch64的实现过程,因此我们也分为了Register,Immediate,LogicalImmediate,Operand,Extend和Shifte。
首先需要分析的是$XLEN$,对于该字段而言,RV32对应的则是$XLEN = 32$;而RV64为$XLEN = 64$:
1 | enum RegisterWidth { |
对于Register类型而言,我们还是对RegisterId进行一个封装:
1 | class Register { |
这里有一个疑惑:RV的官方手册中对于指令的长度有记录,RV64是基于RV32而来的,其给出的指令长度也是$32bits$的,只是立即数和操作数数据会被扩展为$XLEN$大小,但在这里我们的getWidth返回$64bits$是否会有问题?
然后我们就需要简单封装我们的立即数Immediate和LogicalImmediate:
1 | class Immediate { |
然后再封装Shift和Extend:
1 | enum Extend : uint8_t { |
可以看见,RV64中的Shift和Extend也完全参照Aarch64的一个实现。那么对于Operand就不再多余赘述。
最后,我们需要和Aarch一样,继承最开始的Assembler,对RV64的结构进行一个实现:
1 | class AssemblerRiscv64 : public Assembler { |
RV INST
**对于RV而言,其指令集分为了大致五个类型,其中每一个类型的结构都大致相同,因此,我们可以通过宏直接对相同结构的指令进行实现,而不需要手动实现(主要为RV32)**。
因此,这里便提供了宏EMIT_INSTS和AssemblerRiscv64::INSTNAME进行实现:
1 |
在这里,我们主要分析EMIT_R_TYPE_INSTS()和EMIT_R_TYPE_INST这两个宏,有了这两个宏的理解能力,再去分析其他宏就信手拈来了。
首先我们分析内层的ENIT_R_TYPE_INST宏,该宏是R型指令实现的具体接口,所有的R型指令均可以通过该宏进行实现:
1 |
可以看见,EMIT_R_TYPE_INST接受两个参数,第一个则是实例化函数的名字,第二个则是其opcode和funct的结合。因为,在RV中,opcode和funct的组合便足以确定一条确切的指令。
1 | enum AddSubOpFunct { |
可以看见,EMIT_R_TYPE_INSTS则是所有R型指令实现的入口,通过在EMIT_R_TYPE_INSTS宏中定义对应的实例化名字和OpFunct,就能够通过EMIT_R_TYPE_INST实现对应确定的指令处理的函数。
至此,RV64在Aarch64的结构便分析完毕了。
剩余任务分析
| INST | TYPE | INST | TYPE |
|---|---|---|---|
| Jr | J | Blr | J |
| Br | B | Ret | J |
| SLLIW | I | SRLIW | I |
| SRAIW | I | SLLI | I |
| SRLI | I | SRAI | I |
| CSRRW | I | CSRRS | I |
| CSRRC | I | CSRRWI | I |
| CSRRSI | I | CSRRCI | I |
| ADDIW | I | FENCE | I |