CephV10.2.1: Overall Architecture
本节主要对Ceph的系统架构进行介绍。
Ceph的设计目标
Ceph的设计目标是构建大规模的、具有高可用性的、高可扩展性的、高性能的分布式存储系统。
系统的高可用性指的是系统某个部件失效后,系统依然可以提供正常服务的能力。一半用设备部件和数据的冗余来提高可用性。Ceph通过数据多副本、纠删码来提供数据的冗余。
高可扩展性指的是系统可以灵活地应对集群的伸缩。一般值两个方面,一方面指集群的容量可以伸缩,集群可以任意地添加和删除存储节点和存储设备;另一方面指的是系统的性能随集群的增加而线性增加。
Ceph基本架构

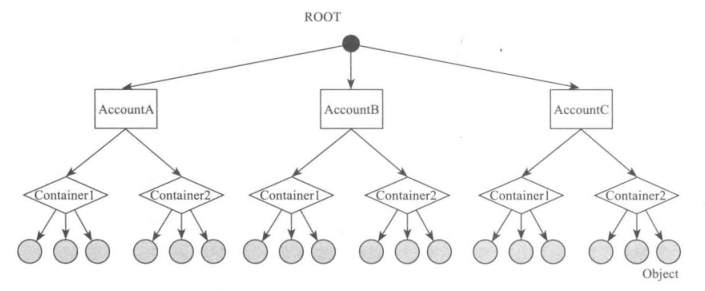
Ceph的整体架构由三个层次组成:
- 最底层/最核心的部分RADOS对象存储系统,基于RADOS($Reliable, Autonomous, Distributed\ object\ store$),是一个可靠的、自组织的、可自动修复、自我管理的分布式对象存储系统。内部包括
ceph-osd后台服务和ceph-mon监控 librados层用于本地或者远程通过网络访问RADOS对象存储系统- Ceph的存储接口实现层
- 块存储接口,通过
librbd提供了块存储访问接口。可以为虚拟机提供虚拟磁盘,或者通过内核映射为物理主机提供磁盘空间。 - 对象存储接口,目前提供了两种类型的API,
- AWS S3 API
- OpenStack Swift API
- 文件存储接口,提供了两种类型的接口,文件系统的元数据通过
MDS访问,而数据直接通过librados访问- 标准Posix接口
libcephfs
- 块存储接口,通过
Ceph客户端接口
RBD
RBD($Rados\ Block\ Device$)通过librbd对应用提供块存储,主要面向云平台的虚拟机提供虚拟磁盘。
目前RBD提供了两个接口,一种是直接在用户态中实现,通过QEMU Driver供KVM虚拟机使用。另一种在操作系统内核态中实现了一个内核模块。通过该模块可以把块设备映射给物理主机,由物理主机直接访问。
块存储既需要有较好的随机I/O,有要求有较好的顺序I/O,且对延迟有比较严格的要求。
CephFS
CephFS通过在$RADOS$基础之上增加了$MDS(Metadata\ Server)$来提供文件存储。其提供了libcephfs和标准的POSIX文件接口。CephFS通过NFS或CIFS协议提供文件系统或文件目录文件。
RadosGW
$RadosGW$基于librados提供了和Amazon S3接口以及OpenStack Swift接口兼容的对象存储接口。可将其简单地理解为提供基本文件的上传和下载的需求:
- 提供$RESTful\ Web\ API$
- 采用扁平化数据组织形式
RESTful存储接口
其简单的提供了GET、PUT、DEL等接口,对应文件的上传、下载、删除、查询等操作。
扁平化数据组织形式

RADOS
$RADOS$是Ceph存储系统的基石,它完成了一个存储系统的核心功能:
- Monitor模块为整个存储集群提供全局的配置和系统信息
- CRUSH算法实现对象的寻址过程
- 完成对象的读写以及其他数据功能
- 提供数据均衡功能
- 通过Peering完成一个PG内存达成数据一致性的过程
- 提供数据自恢复的功能
- 提供克隆和快照功能
- 实现对象分层存储的功能
- 实现数据一致性检查工具Scrub
Monitor
$Monitor$是一个独立部署的daemon进程。通过组成Monitor集群来保证自己的高可用性。Monitor集群通过Paxos算法实现了自己数据的一致性。它提供了整个存储系统的节点信息等全局的配置信息。
$Cluster\ Map$中保存了系统的全局信息,主要包括:
- Monitor Map
- 集群的fsid
- 所有Monitor的地址和端口
- current epoch
- OSD Map
- 所有OSD的列表,和OSD的状态等
- MDS Map
- 所有的MDS的列表和状态
$Cluster\ Map$是直接保存在$Monitor$的内存中的,不过我们可以通过$mon/store.db/*.sst$文件进行查看:
1 | ceph-kvstore-tool rocksdb */mon.a/store.db/*.sst list |
需要注意的是:该文件中的内容很多,不宜查看。
而$Monitor\ Map$、$OSD\ Map$和$MDS\ Map$都是保存在rocksdb的数据库中,因此也无法直接查看,我们可以通过Ceph命令进行查看:
1 | ceph mon getmap -o ./monmap.bin |
由于我启动时只启动了一个MON节点,因此这里只会输出一个MON节点信息,fsid($File\ System\ ID$)是一个唯一标识符,用于识别和区分 Ceph 集群。每个 Ceph 集群在初始化时都会生成一个 fsid,并在集群的配置文件和元数据中进行存储。fsid 是一个 128 位的 UUID,以十六进制格式表示。
其余节点的信息均可以通过以下命令查看:
1 | # 方式一 |
对象存储
在这里的对象均指$RADOS$对象,需要和$RadosGW$的SE或Swift对象区别开来。对象是数据存储的基本单元,一般默认$4MB$大小,如下图所示

一个对象由三部分组成:
- 标识(ID),唯一标识一个对象
- 数据,在本地文件系统中对应一个文件,对象的数据均保存在文件中
- 元数据,以$Key-Value$的形式保存,$RADOS$以$LevelDB$等本地KV存储系统来保存对象的元数据
pool & PG
$pool$是一个抽象的存储池,其规定了数据冗余的类型以及对应的副本分布策略。目前实现了两种类型的$pool$:
- $Replicated$
- $Erasure\ Code$
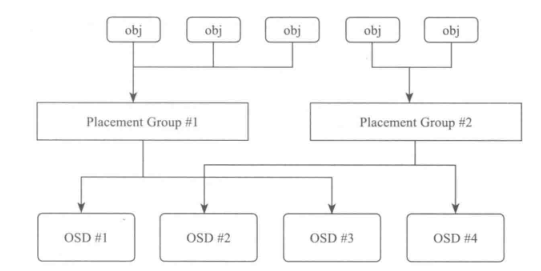
一个$pool$由多个$PG$组成。$PG(Placement\ Group)$从名字上可理解为一个放置策略组,它是对象的集合,该集合的所有对象都具有相同的放置策略:对象的副本都分布在相同的$OSD$列表上,一个对象只能属于一个PG,一个PG对应于放置在其上的OSD列表,而一个OSD上可以分布多个PG。

- $PG1$和$PG2$都属于同一个$pool$,所以都是副本类型,并且都是两副本
- $PG1$和$PG2$都包含许多对象,$PG1$上的所有对象,主从副本分布在$OSD1$和$OSD2$上,$PG2$上的所有对象的主从副本都分布在$OSD2$和$OSD3$上
- 一个对象只能属于一个$PG$,一个$PG$包含多个对象
- 一个$PG$的副本分布在对应的$OSD$列表中,在一个$OSD$上可以分布多个$PG$
对象寻址过程
对象取址过程指的是查找对象在集群中分布的位置信息,该过程分为两步:
- 对象到$PG$的映射。这个过程是静态$Hash$映射(加入$pg\ split$后实际变为动态$Hash$映射),通过对$object_id$计算出$hash$值,使用该$pool$的$PG$的总数量$pg_num$对$hash$取模,就能够得到该对象所在的$PG$的$id$:
1 | pg_id = hash(object_id) % pg_num |
- $PG$到$OSD$列表映射。这里指$PG$上对象的副本如何分布在$OSD$上,使用了Ceph创新的$CRUSH$算法实现:
数据读写过程
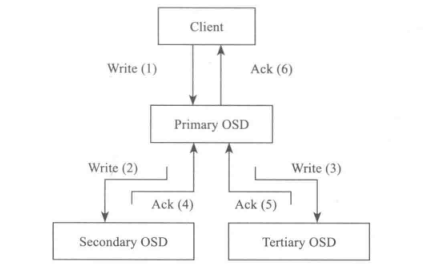
- Client向该$PG$所在的主$OSD$发送写请求
- 主$OSD$接收到写请求后,同时向两个$OSD$发送写副本的请求,并同时写入主$OSD$的本地存储中
- 主$OSD$接收到两个从$OSD$发送写成功的$ACK$应答,同时确认自己写成功,就向客户端返回写成功的$ACK$应答
写操作中,主$OSD$必须等待所有从$OSD$返回正确应答,才能向客户端返回写操作成功。
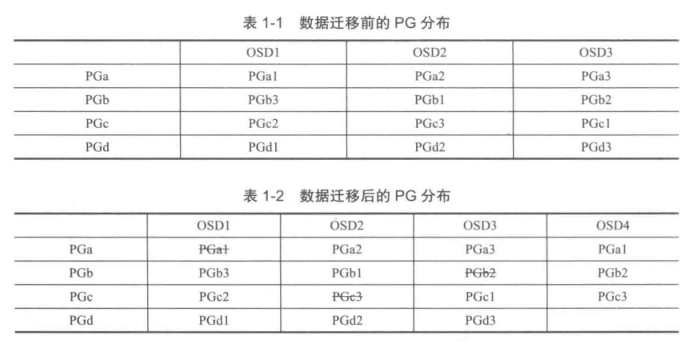
数据均衡
当在集群中添加一个新OSD存储设备时,整个集群会发生数据的迁移,使得数据分布达到均衡。Ceph数据迁移的基本单位是$PG$,即数据迁移是将$PG$中的所有对象作为一个整体来迁移。
迁移触发的流程为:新加入一个OSD,改变系统的$CRUSH\ MAP$,从而引起对象寻址过程中的第二步,$PG$到$OSD$列表的映射发生了变化。从而引发数据的迁移。
Peering
当OSD启动,或者某个OSD失效时,该OSD上的主$PG$会发起一个Peering的过程。Ceph的Peering过程指的是一个$PG$内的所有副本通过$PG$日志来打成数据一致的过程。
当Peering完成之后,该$PG$就可以对外提供读写服务。此时的$PG$的某些对象可能处于数据不一致的状态,则被标记出来,需要恢复。系统优先恢复该对象,才能继续完成写操作。
Recovery & Backfill
纠删码
快照和克隆
$SnapShot$是一个存储设备在某一时刻的全部只读镜像。而$Clone$是在某一时刻的全部可写镜像。
$RADOS$对象存储系统本身支持$Copy-on-Write$方式的快照机制。基于这个机制,Ceph可以实现两种类型的$SnapShot$:
- $pool$级别,给整个$pool$中的所有对象统一做快照操作
- 用户自定义快照,$RBD$快照实现就属于这一级别
Cache Tier
$RADOS$实现了以$pool$为基础的自动分层存储机制。在第一层可以设置$cache\ pool$,其为高速存储设备;第二层为$data\ pool$,使用大容量低速存储设备,可以使用EC模式来降低存储空间。
通过$Cache\ Tier$,可以提高关键数据或热点数据的性能,同时降低存储开销:
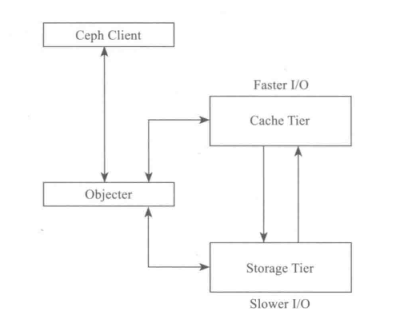
- Ceph Client对于Cache层是透明的
- Objecter负责请求是发送给Cache Tier层,还是发给Storage Tier层
- Cache Tier层为高速I/O层,保存热点数据,或称为活跃的数据
- Storage Tier层为慢速层,保存非活跃的数据
- 在Cache Tier层和Storage Tier层之间,数据根据活跃度自动进行迁移
Scrub
$Scrub$用于系统检查数据一致性,通过在后台定期扫描,比较一个$PG$内的对象分别在其他$OSD$上的各个副本的元数据和数据来检查是否一致。
根据扫描内容分为两种:
- 只比较对象各个副本的元数据:代价小、效率高,对系统影响小
- $deep\ scrub$,不仅需要比较元数据,还需要比较数据