rCore ch3 detail
本篇文章是帮助初学者加快理解rCore的设计原理的文章,并不设计任何关于opencamp实现相关。部分细节参考rCore Tutorial Book chapter3 和 rCore Tutorial Guild chapter3。
如有任何问题,请到对应仓库(nya blog repo)下提出相关issue,参见格式:[Book Name]: Question
下面,我会以我们实际阅读代码的角度来依次分析rCore的具体实现细节,当然部分简单机制会被忽略。
在开始分析rCore操作系统的具体实现时,我们首先需要确保开发环境的正确性。通过执行以下命令切换到ch3分支并验证其可运行性:
1 | git checkout ch3 |
面对复杂的操作系统实现,合理的分析顺序能显著提高理解效率。在rCore项目中,我建议采用以下分析路径:
- 构建系统分析(os/Makefile)
- 用户程序分析(user/src/lib.rs)
- 内核入口分析(os/src/main.rs)
构建系统是理解整个项目的关键入口。我们重点分析os/Makefile中make run的执行流程:
1 | build: $(KERNEL_BIN) |
在os/Makefile中,make run依赖于build,而build会依赖于kernel,在kernel中,会做两件事情:
- 编译出
os中需要的应用程序,用来验证我们的多道程序操作系统 - 编译出
os可执行文件,或者说内核镜像文件,用于启动我们的内核
因此,我们现在讲目光跳转到user中。
User
进入user目录后,我们首先也需要讲目光放在user/Makefile身上,其中,我们主要关注两个点:
- 内核需要的
binary是如何产出的 binary的内存布局是如何的
对于上述的两个重点,在下面会被同时涉及到:
1 | binary: |
在chapter3中会调用一个build.py脚本进行具体的操作:
1 | base_address = 0x80400000 |
在该构建脚本中,关键点在于 app_id 会随着应用程序的生成而递增,从而确保每个编译出的用户程序的起始地址(.text.entry 段)均不相同。这一机制与 chapter2 的实现形成鲜明对比,后者采用固定地址加载方式,而当前方案通过动态计算 base_address + step * app_id 来分配入口地址,确保不同应用程序在内存中的执行位置相互隔离。
接下来,我们需要关注 user/src/lib.rs 文件,其中定义了用户程序的入口逻辑。该文件包含两个关键部分:
1. _start 函数:作为用户程序的初始入口点,由链接脚本显式定位到 .text.entry 段,负责初始化环境并调用 main 函数。
2. 弱符号 main 函数(#[linkage = “weak”]):通过弱符号机制允许不同用户程序提供自己的 main 实现,而链接器会在加载时解析到正确的版本。这种设计实现了入口点的统一管理,同时支持不同应用程序的灵活逻辑。
1 |
|
在用户程序构建过程中,_start函数被显式地定位到src/linker.ld链接脚本中定义的.text.entry段,该段作为用户程序的入口点。通过build.py编译脚本的配置,.text.entry段的起始地址被动态计算为base_address + step * app_id,其中base_address是基地址,step为地址间隔,app_id为应用程序标识符。这种地址分配机制确保了不同用户程序被载入内核后,其入口点位于互不重叠的独立内存区域,从而避免执行地址冲突。
在程序执行流程中,_start函数会进一步调用exit(main(argc, v.as_slice()))。此处引用的main函数被声明为弱符号(weak symbol),这种设计允许在链接阶段存在多个main函数定义。最终链接器会根据实际加载的用户程序选择对应的main函数实现,从而实现多态入口机制。该架构既保持了入口点的统一性,又支持不同用户程序拥有独立的业务逻辑入口。
至此,用户态程序的准备工作已全部完成,其核心机制可总结如下:
- 动态基址分配
- 剥离 ELF 信息的二进制文件
- 编译生成的用户程序被处理为纯二进制文件(binary),移除了 ELF 格式的元数据(如节头表、符号表等),仅保留可执行代码和数据。
- 内核可直接加载这些轻量化的二进制文件,无需解析复杂 ELF 结构,提升了运行效率。
- 标准化入口与弱符号机制
Kernel
在 rCore 操作系统的构建流程中,用户程序的编译与内核镜像的生成遵循严格的自动化构建策略。当用户程序完成编译后,os/Makefile 会立即触发 cargo build 命令以生成最终的内核镜像。
为确保用户程序能够正确嵌入内核并建立可执行环境,rCore 在编译前通过 构建脚本(os/build.rs) 执行关键配置操作:
1 | let mut f = File::create("src/link_app.S").unwrap(); |
在 rCore 操作系统的构建过程中,os/build.rs 脚本会在编译阶段动态生成 os/src/link_app.S 汇编文件,其结构如下所示:
1 | .align 3 |
在完成用户程序的静态嵌入与内核镜像的构建后,系统已具备启动条件。但在正式运行内核之前,需深入理解以下关键模块的设计与协作机制。
Load & Task
在操作系统的设计与实现中,每个任务(Task)、程序(Program)或进程(Process)均需通过一个核心数据结构来维护其执行状态和上下文信息。以传统操作系统理论中的进程控制块(Process Control Block, PCB)为参照,rCore操作系统采用了任务控制块(Task Control Block, TCB)这一抽象结构,用于集中管理应用程序的元数据、资源描述符、执行上下文以及调度相关属性,从而实现对任务生命周期的全流程管控:
1 | pub enum TaskStatus { |
在操作系统的多任务管理机制中,单个 任务控制块(Task Control Block, TCB) 仅能维护一个任务的执行视图。为了全局管理所有任务的调度与状态,rCore 引入了 任务管理器(TaskManager) 作为顶层抽象,负责维护系统中所有 TCB 的集合。
然而,在多任务并发环境下,直接访问 TCB 可能导致数据竞争或状态不一致问题。为此,rCore 采用 内部封装(TaskManagerInner) 的设计模式,将核心任务管理逻辑(如任务调度、状态切换、资源分配等)封装在受保护的内部结构中,并通过 同步原语(如互斥锁或原子操作) 确保线程安全。
1 | pub struct TaskManager { |
在介绍更多之前,我们还需要了解一下任务上下文。在操作系统的任务调度机制中,任务上下文(Task Context) 是实现多任务并发的核心抽象,其本质是任务执行状态的快照,用于在任务切换时保存和恢复关键寄存器状态。
1 | pub struct TaskContext { |
ra(return address):保存任务切换后应跳转的指令地址(如 __restore 或用户程序入口)。在上下文切换时,CPU 通过 ret 指令返回到 ra 指向的地址,实现执行流的无缝衔接。sp(stack pointer):维护任务的独立栈空间。每个任务需拥有专属内核栈(或用户栈),sp 确保切换后能正确访问局部变量和函数调用链。sn(callee-saved register):RISC-V 规定这些寄存器由被调用函数(Callee)保存。任务切换时需手动保存它们,避免破坏任务自身的计算状态(如循环变量、指针等)。
接下来我们就可以继续分析内核的执行:在rCore操作系统初始启动阶段,系统通过lazy_static宏实现了TASK_MANAGER全局变量的惰性初始化。对于每个用户任务,内核会调用goto_restore(init_app_cx(i))函数进行上下文初始化:其中init_app_cx(i)负责在内核栈中构建指定任务的初始执行上下文,其返回值作为该任务的内核栈指针;而goto_restore则将该任务的返回地址设置为__restore符号地址,从而建立从内核态到用户态的正确执行流切换路径。
在任务管理初始化完成后,系统通过load_apps函数加载所有用户程序到物理内存。这些用户程序的加载地址严格遵循build.py构建脚本中预设的入口地址配置,确保用户态程序的二进制映像被精确映射到预期的内存区域,为后续的任务执行建立正确的地址空间布局。
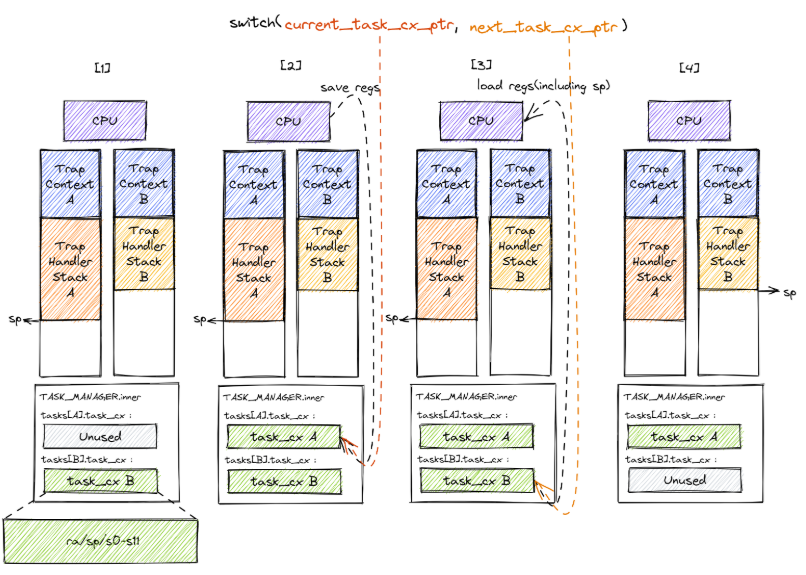
此时,我们还需要一个能够切换任务上下文的函数,因此使用switch.S来实现:
- 保存当前任务的
sp - 保存当前任务的
ra - 保存当前任务的
sn - 载入下一个任务的
ra - 载入下一个任务的
sn - 载入下一个任务的
sp - 最后通过
ret指令返回到ra(即__restore)指向的地址处继续执行
值得注意的是:__switch只处理内核栈和寄存器的保存与回复,不会涉及用户态的回复和特权级切换,因此需要转入__restore中继续执行。
因从,我们继续分析 run_first_task的全流程会发生什么。run_first_task会取出第一个任务,然后与一个空任务进行交换:
1 | __switch(&mut _unused as *mut TaskContext, next_task_cx_ptr); |
此时,__switch会载入第一个任务的栈和指针,并将ra(__restore)载入,通过ret进入到__restore入口。在Load阶段有一点没有说明的是:
每一个任务在初始化上下文时,都需要载入以下数据:
- 寄存器值
- sstatus寄存器(设置为User模式)
- sepc寄存器(设置为用户程序的入口点)
- sp寄存器(用户栈指针,x[2])
通过查阅RISC-V ISA PREVILEGE Supervisor-Level ISA可以了解到:
- sstatus寄存器用于恢复CPU特权级状态(例如重新允许中断、切换回用户态)
- sepc寄存器用于设定
sret指令的返回地址(即返回到用户程序的哪条指令)。 - sscratch寄存器用于保存用户栈指针,用于后续交换栈指针。
并且,在init_app_cx函数中我们将每一个任务的上下文地址压入了内核栈中:
1 | KERNEL_STACK[app_id].push_context(TrapContext::app_init_context( |
因此,这里就有了一个很清晰的对于用户栈和内核栈的概念了:
1 | TaskContext |
现在我们重新看回run_first_task的流程,当我们执行到__restore时,我们直接载入第一个任务的sstatus、sepc和sp指针:
1 | ld t0, 32*8(sp) |
此时,操作系统已经知道了sret要返回的用户程序入口以及用户程序的栈,然后再载入其他寄存器到操作系统中(注意,此时的sp还是指向的内核栈);载入成功后,我们需要将内核指针移动$34*8$个字节(sizeof TrapContex),然后再通过csrrw交换内核栈和用户栈(此时sscratch -> kstack, sp -> user stack)。
最后,我们通过sret进入到第一个用户程序的入口点,便可以开始执行了。
在系统实现层面,部分开发者可能对任务调度机制存在疑问:为何仅调用run_first_task函数即可完成所有应用程序的执行流程。虽然直觉上可能联想到trap中断机制的作用,但在分析hello_world这类无显式异常触发的用例时仍会产生困惑。需要特别说明的是,当前内核采用了一种精简的设计架构,其任务调度必然依赖trap异常处理机制实现——具体而言,内核在异常处理例程中隐式地执行了任务上下文保存与切换操作,从而实现了多任务的轮转调度。这种设计使得用户态程序无需主动触发异常即可被系统透明地管理,体现了中断驱动式调度(interrupt-driven scheduling)的典型特征。
Trap
对于rCore的trap机制,个人认为rCore trap讲的比较详细,便不再过于赘述。可以给出一些debug图例仅供参考。
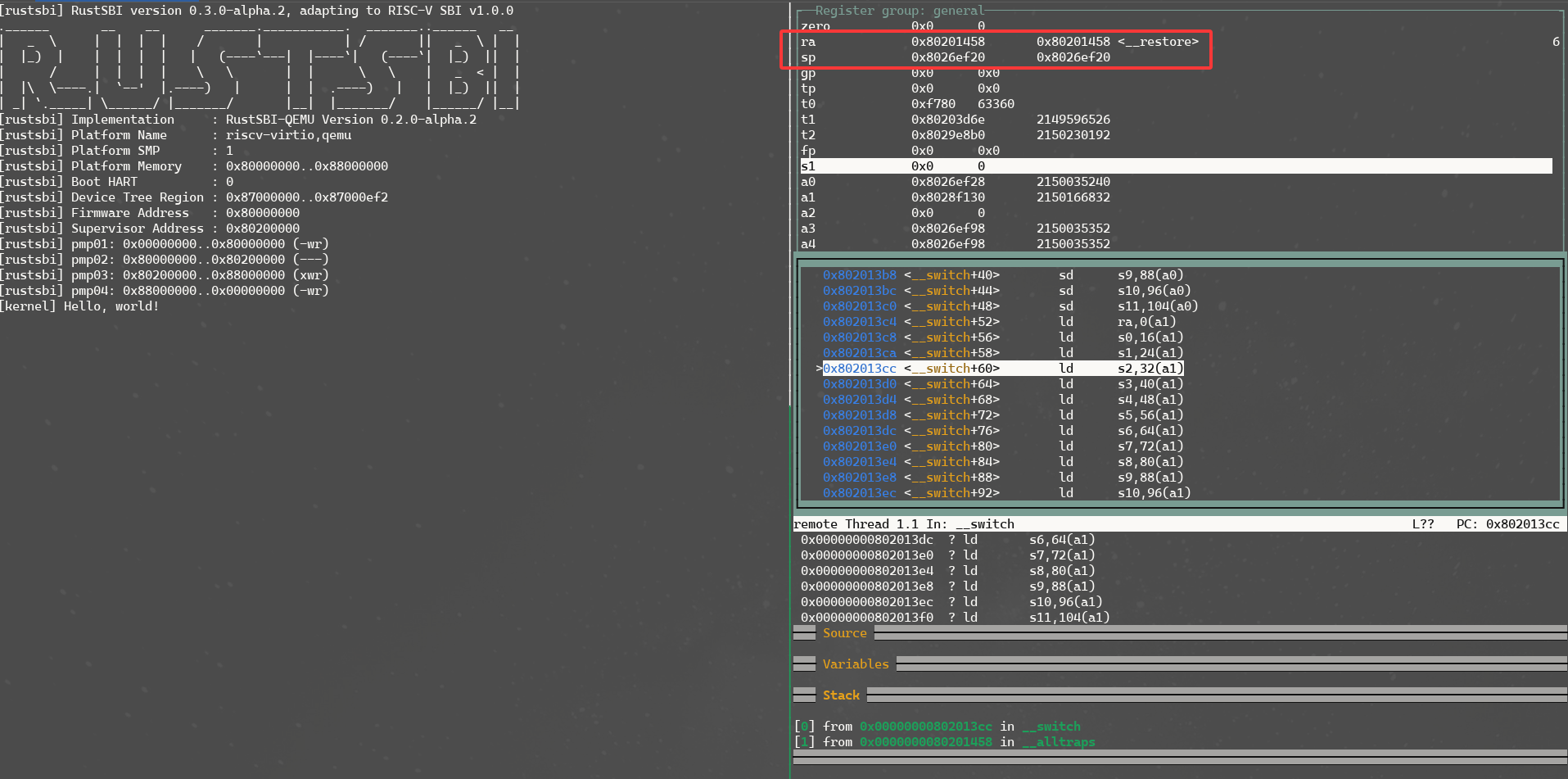
上图是关于__switch函数中的ra和sp地址的查看。

上图是关于__restore函数中的kstack地址的查看。
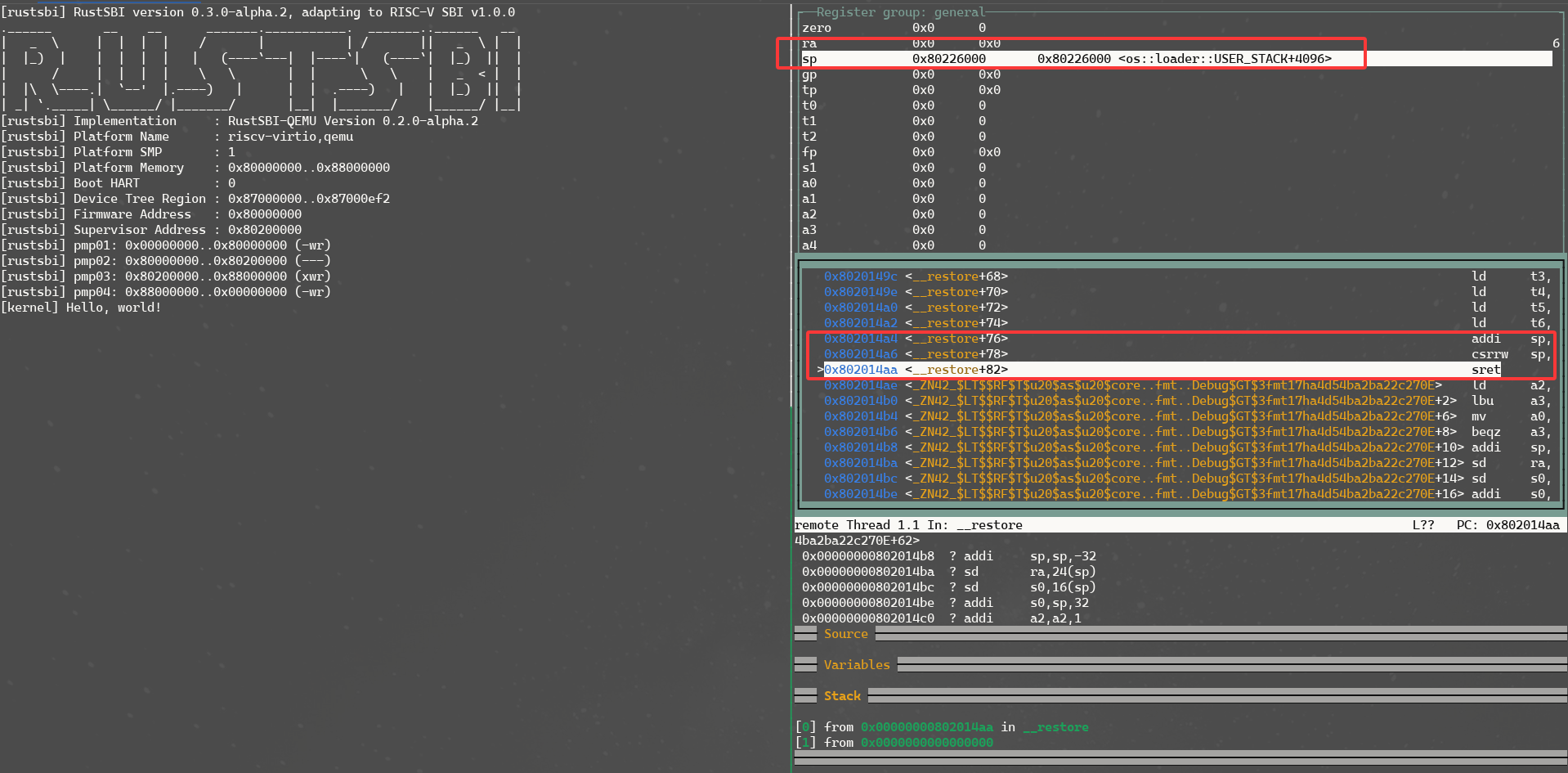
上图是关于__restore函数中的user stack地址的查看。
Syscall
对于操作系统来说,系统调用是一件十分简单的事情(如果你已经搞明白了trap机制的原理),系统调用本质上就是个精心设计的陷阱(trap)。当你理解了ecall这个魔法指令,实现系统调用就像搭积木一样简单。:
1 | pub fn syscall(id: usize, args: [usize; 3]) -> isize { |
当然,如果你了解过xv6-riscv的话,系统调用也不在话下:
1 | .globl start |
现在我们回到上面没有解决的问题:为什么类似于hello_world的应用程序能够自动的切换为下一个应用程序呢?
我们需要回忆起:我们在编译出应用程序的binary时,使用的weak main,因此,当我们执行到应用程序的_start入口时可以发现:
1 |
|
这里的main调用居然包裹了一个exit调用,而这个exit调用正是一个系统调用sys_exit,因此,当hello_world执行完毕之后,会因为系统调用而进入trap_handler从而切换了下一个应用程序:
1 | pub fn exit_current_and_run_next() { |
至此,rCore的第三章实现流程便分析完毕了。